Knowing when to look – A human’s perception in Machine Intelligence
In recent decades, image captioning powered by Deep Learning and Attention Mechanism has been widely adopted. Many models achieved significant results, however, a major number of these models might not take account of the fact that many words such as ‘a’, ‘the’, ‘of’, etc. do not directly attend to visual information or regions on images. These kinds of words seem to be generated by the language model which is constructed through the decoder (RNN or LSTM models) of an image captioning framework. In order to leverage this issue, the paper of Jiasen Lu named “ Know When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning” [1] proposed a method to clarify which information the model will base on to formulate the description. In addition, the papers also adapt the traditional attention used in image captioning by a novel algorithm called Adaptive Attention.
To begin with, let’s review the theory of Attention Mechanism[2] and LSTM[3], the two back-born for the proposed solution.
Attention in Computer Vision
Whoever wants to deploy an attention algorithm on Computer Vision, they must cite the paper “Show, Attend and Tell: Neural Image Caption Generation with Visual Attention”[4]. Too famous to skip. In this paper, Attention was estimated by three equations below:
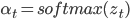
Where ![]() is the hidden layer in LSTM decoder, V is the set of regions in an image V =
is the hidden layer in LSTM decoder, V is the set of regions in an image V =![]() regions.
regions. ![]() is the context – vector, which is also the context inputted into LSTM cells. [3]
is the context – vector, which is also the context inputted into LSTM cells. [3]
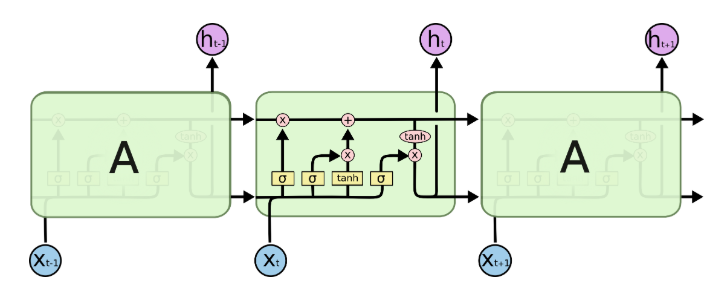
LSTM Structure
LSTM is a structure that is to resolve the problem of sequence dependency in recurrent neural networks. Instead of constructing only one tanh function, LSTM contains different blocks. For me, no one could describe the theory of LSTM as detailed as Christopher Olah did in his blog [3]. I summarize here some salient points:
Each cell of LSTM is identical with an input set at time t including ![]() which are context vector, input vector, and previously hidden state vector respectively.
which are context vector, input vector, and previously hidden state vector respectively.

The core idea behind LSTM
On the top of a cell in LSTMs, a horizontal which runs through the cell is the context information. Mr. Colah called this is “a conveyor belt” which may absorb only some minor change when it flows along with the cell.
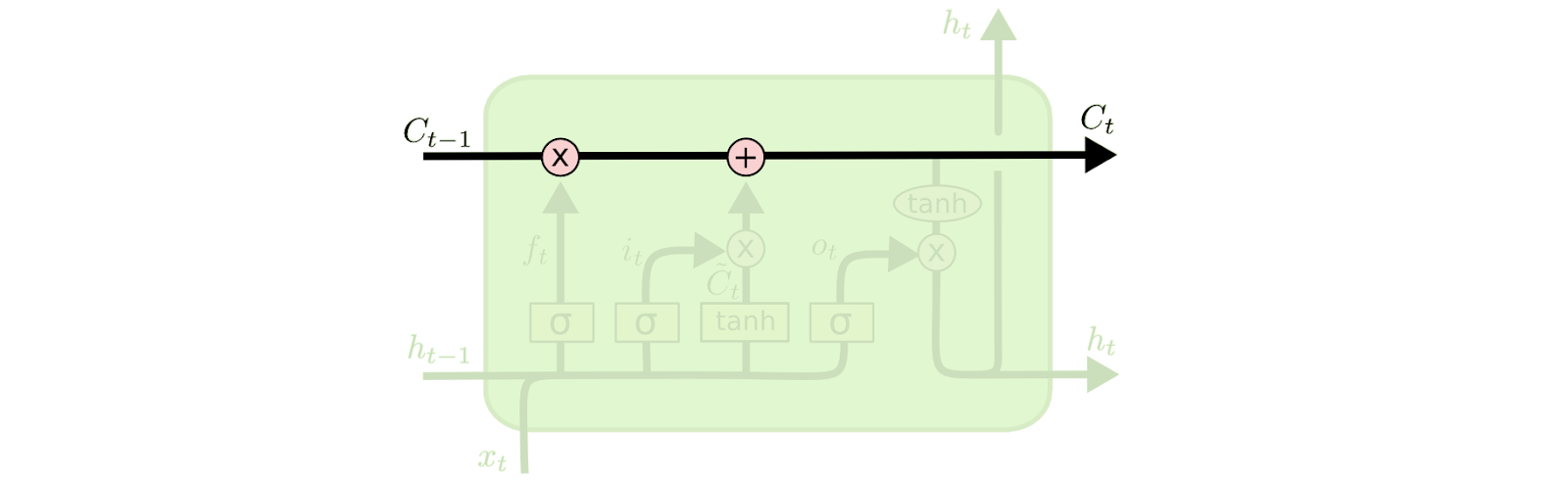
In order to adjust the context information, LSTMs introduce cell gates composed out of a “sigmoid neural net layer and a ![]() multiplication operation”.
multiplication operation”.
As you already know, sigmoid’s output values are in the range of 0 and 1. In other words, they defined how much information will be eliminated or added when the context vector goes through the cell. 0 means no information will be kept and 1 means the whole information will be kept.
In case that attention enters the game, attention contributes to the formation of the context vector.
LSTM Step by Step
The first gate called forget gate f, which defined the number of information will be transferred in a cell. This gate looks at the previous hidden state and an input x and output a number to multiply with the previous context vector.
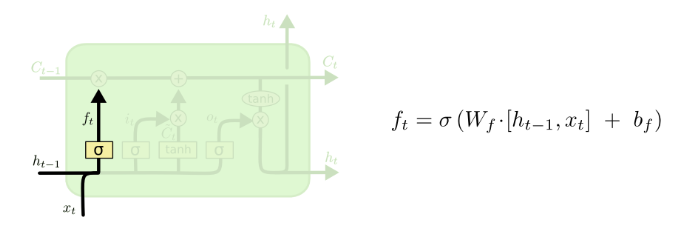
The second block is called input gate i. This gate contains two branches. The first one produces ![]() after going through a sigmoid layer in order to decide which information will be updated in the cell. The second branch will transfer information through a tanh function to decide how much information will be added to the new cell.
after going through a sigmoid layer in order to decide which information will be updated in the cell. The second branch will transfer information through a tanh function to decide how much information will be added to the new cell.
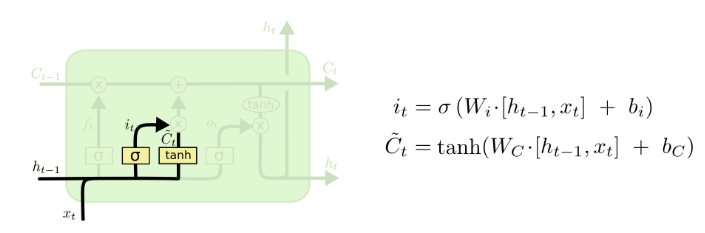
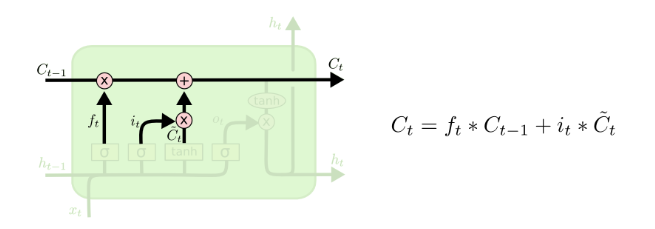
Now, it is time to update the old context vector. The new context vector is a combined vector from the previous context and the input context.
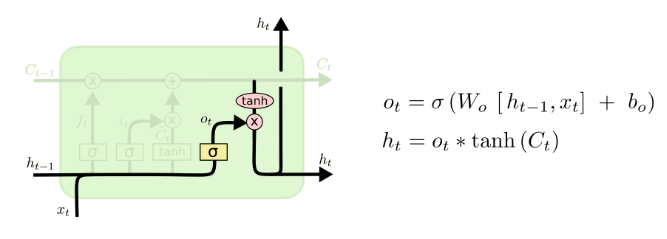
Next, LSTMs would like to produce the output, the hidden state, by multiplying the context vector after applying tanh with sigmoid of input information.
That‘s it. We did finish the review for LSTMs. Understanding the intuitive behind LSTMs’ operations enable us to interpret the structure of language modeling as well as how the model will generate words in Image Captioning.
The paper’s approach
The authors stated that they brought the notion of “sentinel visual” which is not related to any regions in the descriptive image. On the other hand, sentinel visual is a fallback that the model wants to refer to when it could not align a word ( kinds of article ‘a’, ‘an’, ‘the’, or ‘of’, etc) to the images. I guess that is the reason why the authors named “sentinel” to this visual information. Please bear in mind that sentinel visual information would be extracted by using LSTMs or a language model.
If you were me, you would feel how I was about this idea. I am also not amazed why this paper has been cited nearly 500 times. In fact, the idea replicated in Neural Baby Talk in order to generate a slotted template for Image Captioning which improves Bleu Score, an estimated measurement for sequence generation functions, significantly.
Okay! Let’s dig deeper inside the method.
Encoder-Decoder for Image Captioning
Mathematical formula of Image Captioning is:
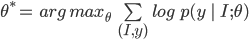
Where ![]() is the input image,
is the input image, ![]() is the parameter of the model, and
is the parameter of the model, and ![]() is the output text
is the output text ![]()
Applying chain rule, and we get this beautiful function ( ![]() but eliminate for convenience)
but eliminate for convenience)
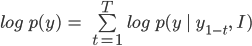
Because ![]() generated by LSTMs, it is certain to formulate in terms of hidden states and context vectors. If you have furrowed brows, you should be back in the early parts of this article to read again about LSTMs.
generated by LSTMs, it is certain to formulate in terms of hidden states and context vectors. If you have furrowed brows, you should be back in the early parts of this article to read again about LSTMs.
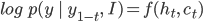
For ![]() . Remember that in the paper, authors noted
. Remember that in the paper, authors noted ![]() as
as ![]() for memory state.
for memory state.
Done for background knowledge! Now, it’s time for the most novel algorithms in Attention. You should know that there are two kinds of visual information: spatial-visual and of course, sentinel-visual. It means this article will discuss both spatial attention and sentinel attention.
Spatial Attention
This attention is formulated by regions in an image and hidden states in LSTMs. I note here the formula:
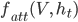
And attention now is:
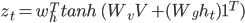
![]() regions. 1 is a vector with all elements set to 1. Ws are parameters to be learnt.
regions. 1 is a vector with all elements set to 1. Ws are parameters to be learnt. ![]() is the attention weight over features in V. and c is the context vector.
is the attention weight over features in V. and c is the context vector.
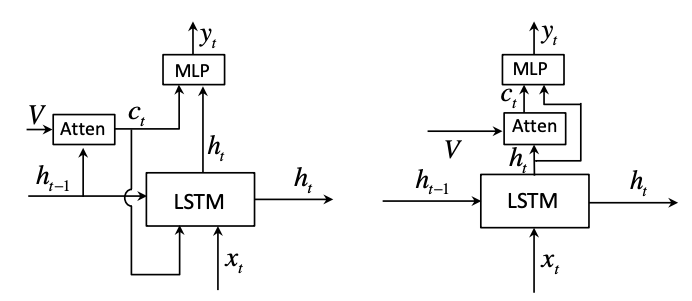
Uhm..m Something ‘s wrong. You should recognize that this attention is estimated by the current hidden state while the old one based on previous hidden states. The reason is the authors adapted the attention into a new form. The below pictures will clear the cloud in your mind.
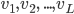
The right attention… you know… it is A RESIDUAL FORM. The author claimed that they could achieve a better result because of this innovation.
Sentinel Attention
Sentinel Attention also finds a weight vector alpha and the context vector. Moreover, it needs a coefficient ![]() – a sentinel gate, to tell the model which kind of visual it will focus on.
– a sentinel gate, to tell the model which kind of visual it will focus on.
Sentinel Visual is an output of the Language Model, so it is easy to define in terms of LSTM.
![]() is exactly the sentinel visual.
is exactly the sentinel visual.
From sentinel visual information and spatial visual information, we obtain a context vector by this combination.
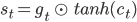
As I mentioned above, ![]() is a sentinel gate which is calculated by estimating the weighted alpha of concatenated
is a sentinel gate which is calculated by estimating the weighted alpha of concatenated ![]()
Why? It’s an exercise for you. But I will put the key here: concatenation and reading the whole paper to find the dimension of all the matrixes which I was too lazy to put them in this article. OK. Only one equation to find the probability of the output word and we finish the paper. This is it:
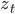
There is much interesting information inside the paper and I recommend that you should open it and read it [1].
[1] Original Paper: https://arxiv.org/pdf/1612.01887.pdf
[2] https://pixta.vn/attention-again-a-long-survey/
[3] https://colah.github.io/posts/2015-08-Understanding-LSTMs/
[4] Show, Attend and Tell: https://arxiv.org/abs/1502.03044
Tác giả: Tony (Lab Team – Pixta Việt Nam)
Like & Follow Pixta Việt Nam để cập nhật các tin tức công nghệ mới và thú vị nhé!
