ResNeSt: Split – Attention, a future backbone for Computer Vision
Since Kaiming He introduced Resnet in 2014, Resnet has become the most robust backbone and been an excellent option for many downstream applications in computer vision. Up until now, there are about 40000 cites from AI researchers around the world for Resnet. Based on the success of Resnet, many researchers proposed their adjusted architecture, which inherits the phenomena of Resnet. Some of them are Resnext, SE-Net, SK-Net, etc.
Even though how powerful Resnet is, this architecture could not exploit cross-channel information. That is also the main reason why other variants of Resnet, which addressed the problem and became fancy approaches in Image Classification, Object Detection, Semantica Segmentation. Last month, Hang Zhang and et al. from the University of California, Davis proposed a new architecture that adopted Resnet and Attention Mechanism called ResNeSt, with S stands for Split-Attention. According to the paper[1], this sturdy model achieved state-of-the-art results in Image Classification on the ImageNet dataset. Moreover, when the authors supplanted Resnet-50 backbone with ResNeSt-50 in Faster-RCNN, which is one of the most famous architectures for Object Detection, they observed the performance increased immensely.
The question is, “why ResNeSt can achieve those wonderful results?” and “whether or not it could be the new backbone model in almost all computer vision applications in the future?”. It is easier to find the answers to the questions mentioned above by breaking down the techniques of ResNeSt, which I am going to do in this article.
The time before ResNeSt.
When I first skimmed the paper ResNeSt: Split-Attention Networks, I immediately realized that this model is an upgraded version of several previous successful models, including Resnet (of course), Resnext, SE-Net, Attention Mechanism, and Gating Mechanism. Since not all of you are familiar with all the above terms, I would like to explain all of them before getting deeper into the intuition of ResNeSt.
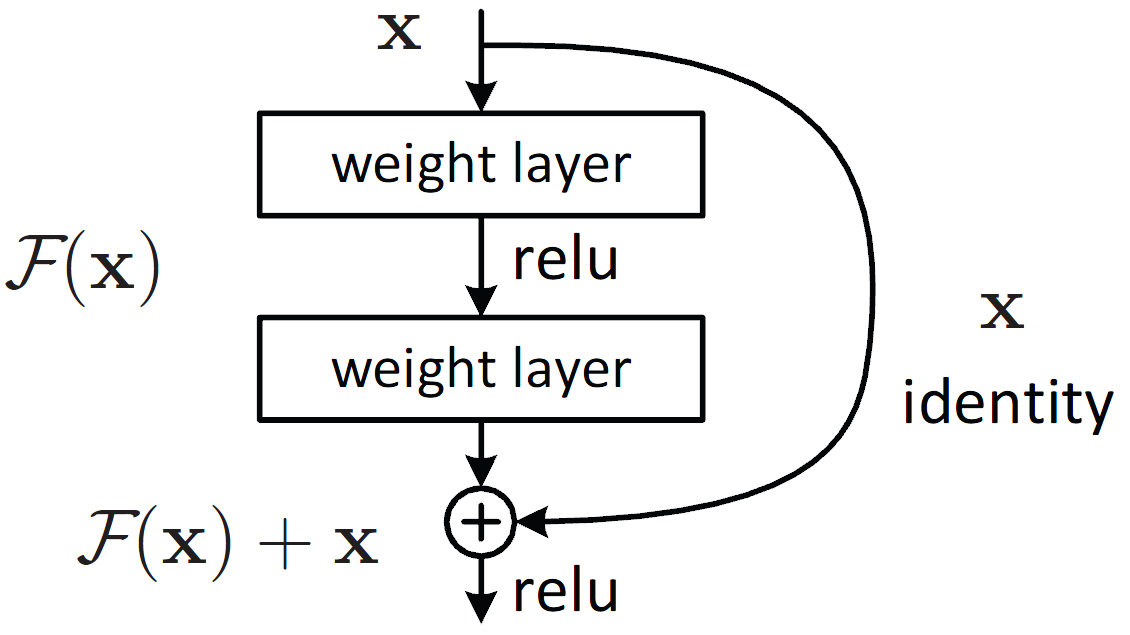
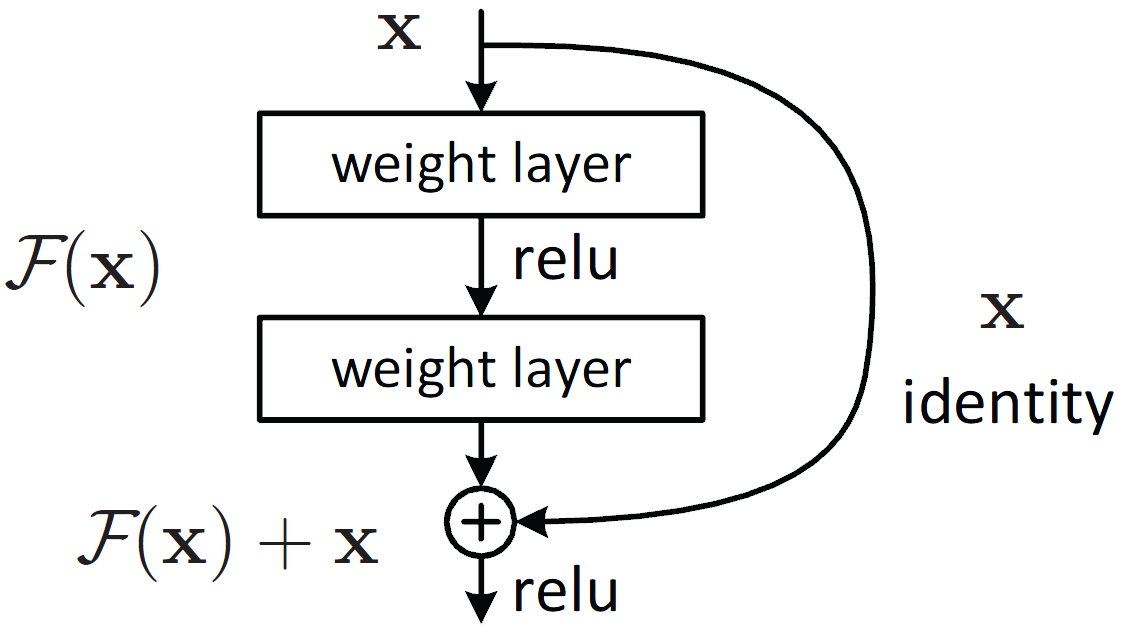
ResNet.
Resnet or residual neural network was introduced by Kaiming He when he was working at Microsoft Research. This structure network of Kaiming inspired by Taylor Expansion, and it mitigates the problem of gradient vanishing when a deep learning network increases the number of layers. A Resnet function is formulated as:
ResNext
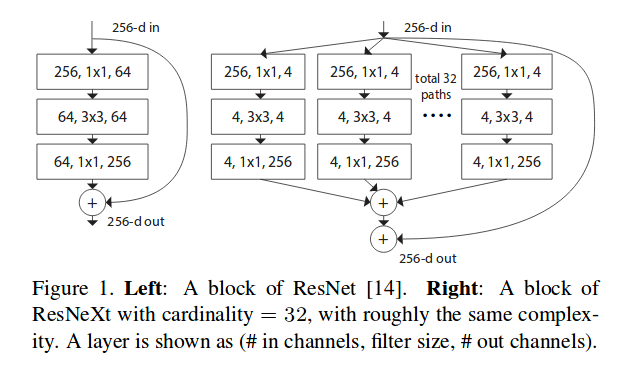
Resnext is a later version of the Resnet model with an introduction of ‘cardinality,’ a new dimension in addition to the width and depth. In fact, ‘cardinality’ is the repeated bottle-neck blocks, which breaks channel information into smaller groups. Due to the strength of these cardinalities, Resnext could achieve a state-of-the-art result in Image Classification in 2016. The most interesting point of this model is that the bottle-neck module could transform 256-dimensional input to only 4-dimensional output. This idea of Resnext will be inherited in ResNeSt in 2020.
Squeeze and Excitation Net
SE stands for Squeeze and Excitation, which apply a gating mechanism on channel dimension of feature maps.The figure described detail three steps in Squeeze and Excitation network:
Transforming input to features map.
Squeezing: applying Global Average Pooling into feature maps in channel dimension
Excitation: applying two linear transformations on the result of Squeezing phase, and then gating it by a sigmoid function.
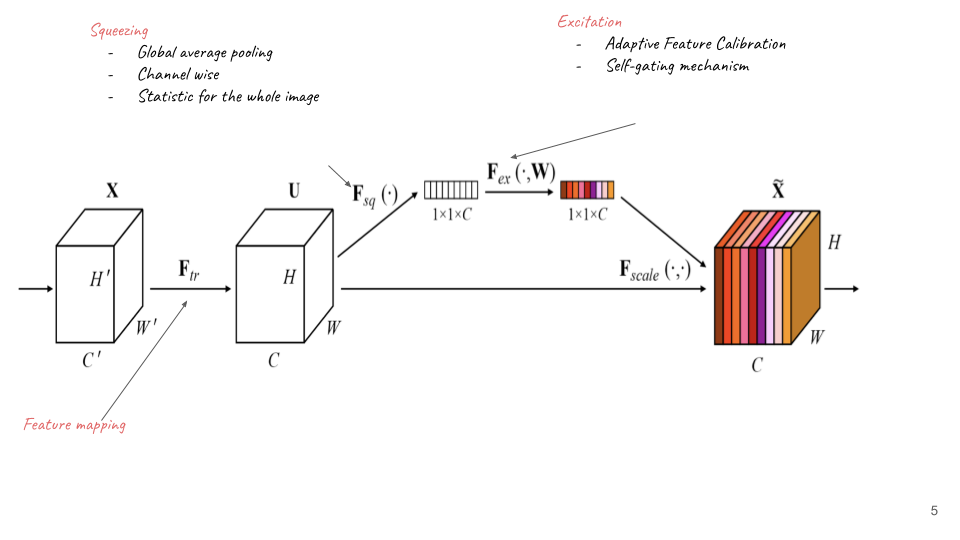
The intriguing point in this model is that SE is a light-weight block, which is easily embedded into other structures such as SE-Resnet or SE-Inception.
ResNeSt
Now, it is time to exploit ResNest. As I mentioned above, when I read the paper by the authors from UC Davis, I was not too surprised because of the idea behind the story. In fact, the idea is not a breakthrough (honestly). Still, it is a wise approach: Cardinality of Resnext and Attention of Squeeze and Excitation Net are combined to formulate a Split-Attention model.
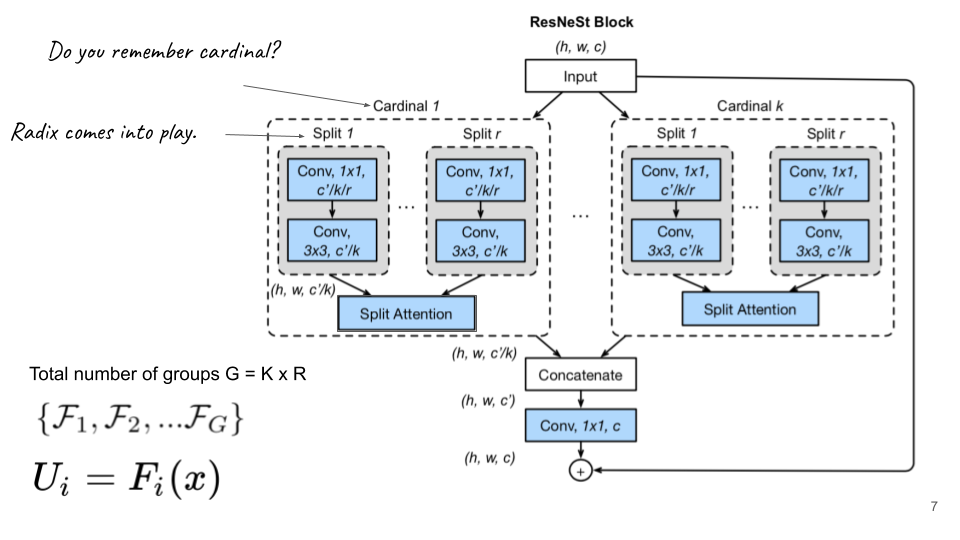
Input feature maps are split into G block where G = number of Cardinality x number of Radix. I hope that you remember Cardinality in Resnext. Radix is the additional path that definitely is the block in the SE net.
Since there are several SE blocks instead of only one block, as described in the original paper of the Squeeze and Excitation model, the split-attention is a modification of the gating mechanism. S The below figure presented details of the steps in the split-attention block.
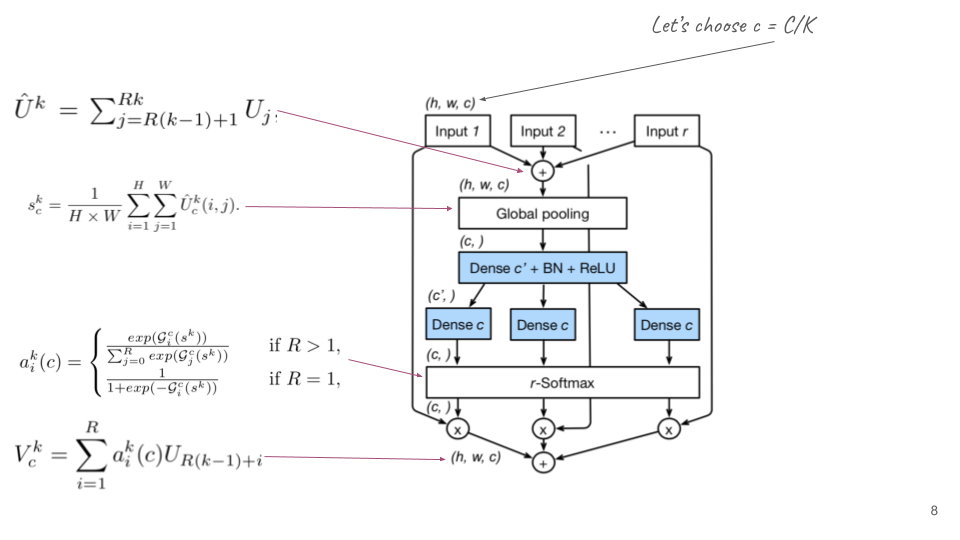
I guess you could understand about 90% of the meaning of the above figure. There is something that the paper did not mention that I would like to discuss here.
Discussion
-
Multi- Dense-c: From the figure, readers could feel confused a little about the number of Dense-c. If you are a fan of Transformer and Multi-head Attention, you can find out the idea behind this action. Yes, it is exactly the idea of multi-head attention, which allows one point to attends several positions simultaneously.
-
Sigmoid or Softmax: The second confusing point is that why R > 1 the authors use softmax while they use sigmoid when R = 1. The reason is that when R = 1, we come back to the original idea of the gating mechanism in SE-net. Moreover, the fundamental intuition is that when R = 1, our softmax function is sigmoid. This is because the exponential functions run from 0 to R, and the summarization in the Softmax function is 1 + exp(x). Thanks to an internship in my company, he is the fastest person at my team to discover this point.
Writer: Tony (Senior Data Scientist – Pixta Vietnam)
Like và follow fanpage của Pixta Việt Nam để cập nhật các thông tin công nghệ hữu ích nhé!
