
The Age of Fast Open-Vocab Detectors
In recent years, the field of object detection has seen transformative advancements, particularly with the rise of open-vocabulary object detection (OVD) models. This is an exciting development from traditional models, which are limited by predefined categories. These models are designed to recognize a vast array of objects beyond those they were explicitly trained on. The surge in research and development in OVD is partly fueled by advancements in multimodal models, particularly through vision-language pre-training.
The Challenge of Open-Vocab Object Detection
Despite these strides, the approach is not without its challenges. Open vocab object detection models face some notable hurdles:
- High Computational Demands: These models require significant computational resources, often rendering them too slow for real-time applications.
- Generalisation Difficulty: Detecting unseen objects with high confidence remains a formidable challenge.
- Data Needs: Large amounts of data is needed for training and optimal model convergence
In this post, I will focus on innovative breakthroughs that aim to enhance speed and efficiency in OVD models, making them more suitable for real-time detection. Specifically, I will explore three models that have set new standards for the inference speed of OVD models: YoloWorld, GroundingDino 1.5 Edge, and OmDet-Turbo.
YoloWorld
YoloWorld, introduced in January 2024, is a groundbreaking iteration of the YOLO model that incorporates open-vocabulary detection capabilities through vision-language modelling and extensive pre-training on large-scale datasets. The model maintains the foundational YOLO architecture but integrates a frozen pre-trained CLIP text encoder for encoding input texts.
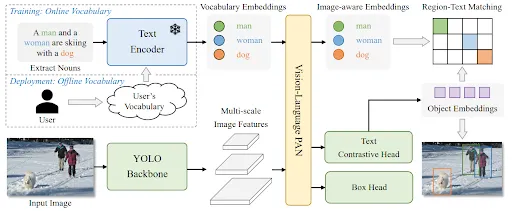
YoloWorld Architecture
Notably, it introduces an innovative Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN) which bridges text features with image features for enhanced visual-semantic representation. RepVL-PAN is a feature enhancer layer that enhances both text and image representation by exploiting cross-modality fusion between image features and text embeddings. It consists of two main building blocks: Text guided-CSPLayer and Image-Pooling Attention. Simply put, these layers help to inject image information into text embeddings, and language information into image features using the concept of attention.
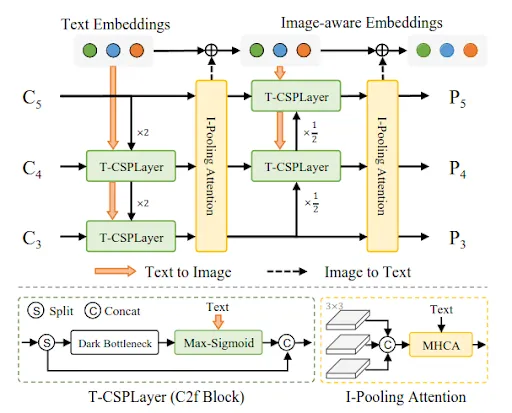
Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN)
YoloWorld’s Speed
So what exactly defines YoloWorld’s speed?
The performance of YoloWorld can be attributed to two components.
Firstly, it uses the YOLOv8 backbone, which, unlike slower Transformer-based models, is faster due to its simpler, lighter CNN-based architecture.
Secondly, reparameterization of pre-defined prompts into the weights of the model eliminates redundant computations. YoloWorld employs a “Prompt-then-detect” paradigm, allowing users to define custom prompts, such as captions or categories. Since the prompts are predefined by the users, they can be processed by the text encoder into offline vocabulary embeddings. These can then be reparameterized into the RepVL-PAN layers by replacing complex mathematical computations with simple convolution layers.
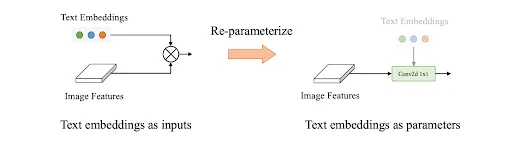
Re-parameterization process in YoloWorld
Reparameterization significantly reduces the model’s parameter count and eliminates the need for an active text encoder during inference. This approach not only speeds up the process but also provides flexibility in adjusting the vocabulary as required.
Overall, these factors help YoloWorld achieve over 20x speedup compared to other state-of-the-art OVD
GroundingDino 1.5 Edge
An alternative to YoloWorld is the Grounding Dino1.5 Edge model.
The model, launched in May 2024, builds on the success of its predecessor, Grounding Dino and was released alongside Grounding Dino 1.5 Pro with the purpose of improving speed for the Edge version and accuracy for the Pro version.
Before diving into Grounding Dino 1.5 Edge, it is important to understand the original Grounding Dino due to their large similarities.
Architecturally, the original Grounding Dino model is structured to integrate language and vision by conceptually training a closed-set detector in three phases: early, mid, and late. These correspond to different fusion strategies, including a feature enhancer, a language-guided query selection, and a cross-modality decoder designed for effective cross-modality fusion.
In essence, these three feature fusion approaches use various context enhancing strategies such as cross-attention and multimodal queries to enrich text-image relationships and understanding.
GroundingDino 1.5 Edge’s Performance
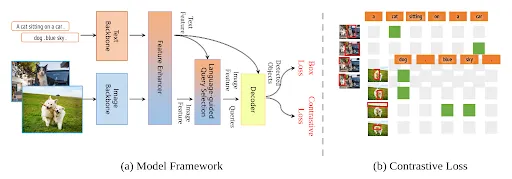
GroundingDino1.5 Architecture
Compared to the original version, the Edge version uses a smaller feature enhancer layer and smaller encoder backbone.
It’s increased speed is achieved by simplifying the model without compromising its performance significantly.
One way is by focusing exclusively on high-level image features to limit computational demands and enhance cross-modality fusion. This cuts down the number of tokens needed to be processed. For better deployment on edge GPUs, it employs vanilla self-attention instead of deformable self-attention and incorporates a cross-scale feature fusion module to integrate lower-level image features. This significantly reduces the complexity present in the enhancer layer which makes it suitable for devices with smaller computing power.
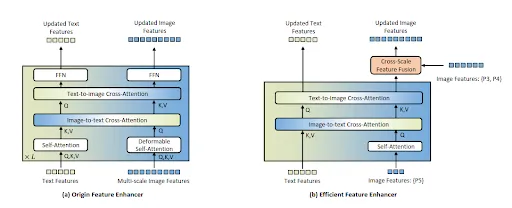
Simplification of Feature Enhancer layer in GroundingDino1.5 Edge
Another notable enhancement is the upgrade to a lighter and more efficient EfficientViT-L1 image encoder. The simpler backbone uses ReLU attention instead of traditional Softmax attention, which reduces the complexity of the attention mechanism while sacrificing little performance.
Altogether, the improvements made to simplify GroundingDino’s archictecture helped improve its speed signifcantly.
OmDet-Turbo
Last but not least, OmDet-Turbo is another addition to the family of fast OVD models.
Introduced in March 2024, it took its inspiration from previous OVD models, OmDet and GroundingDino. It addresses speed bottlenecks in these models by featuring an Efficient Fusion Head (EFH) that dramatically reduces the computational demands typically associated with those OVDs.
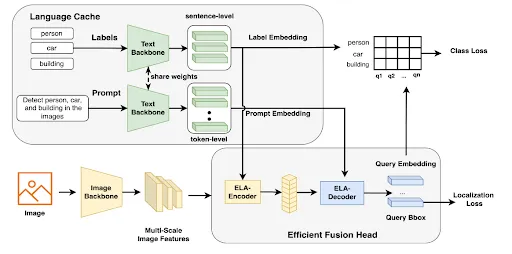
OmDet-Turbo Architecture
OmDet-Turbo’s Speed
OmDet-Turbo’s speed is achieved through efficient feature fusion done using the EFH module.
It is made up of two key components: Efficient Language-Aware Encoder (ELA-Encoder) and Efficient Language-Aware Decoder (ELA-Decoder).
The encoder follows an efficient hybrid encoder that follows similar concepts used in GroudningDino 1.5 Edge. By focusing exclusively on high-level image features, it is able to significantly reduce computational costs. This design aimed to address bottlenecks identified in GroundingDino’s feature fusion layer. Outputs from the ELA-Encoder are then used as query tokens for the ELA-Decoder.
Meanwhile, the decoder uses MHSA and deformable attention to create language-aware multimodal embeddings. This process is more efficient than the cumbersome ROIAlign techniques used in the original OmDet for feature extraction. Together, the EFH is able to achieve improved speed performance.
In addition, the model uses language cache to reduce any redundant computations. Since the model has separate text and image backbones, it is able to store the text embeddings of the labels and prompts in memory or GPU. This avoids having to recompute text embeddings of the same texts during inference.

Speed comparisons across different layers visualising how bottlenecks are addressed
On a whole, OmDet-Turbo’s simplification of fusion layers and cached prompts helped achieved its significant speed
The Road Ahead
While the latest advancements in open-vocab object detection are promising, these models still face challenges in matching the speed and efficiency of closed-set detectors. However, the potential for these technologies to revolutionise various sectors by enabling more generalised and adaptive detection capabilities is immense.
In conclusion, as we continue to push the boundaries of what’s possible in object detection, the innovations within models like YoloWorld, GroundingDino 1.5 Edge, and OmDet-Turbo are paving the way for a future where real-time, open-vocabulary object detection is not just a possibility, but a reality.
Written by Wang Ruijie
