
01Th4
Why I Stopped Debugging LLMs by “Vibes”

When I first started building LLM applications, it was mostly about sending a text string to an API and hoping for the best. But as time goes by, my LLM apps have evolved into complex pipelines involving Retrieval-Augmented Generation (RAG), external tools, and agents, I’ve realized a hard truth: failures rarely come from “the model only”.
Because LLM outputs are inherently non-deterministic, relying on standard debugging methods often left me debugging by pure “vibes.” I would stare at a timeout or a hallucination and guess where the chain broke down.
To build reliable AI systems, I realized I needed a way to consistently answer three crucial questions: What happened? Where did it fail? What changed? This is why I believe observability is absolutely essential, and I rely on a framework of See, Control, and Measure — powered by platforms like Langfuse — to achieve it.
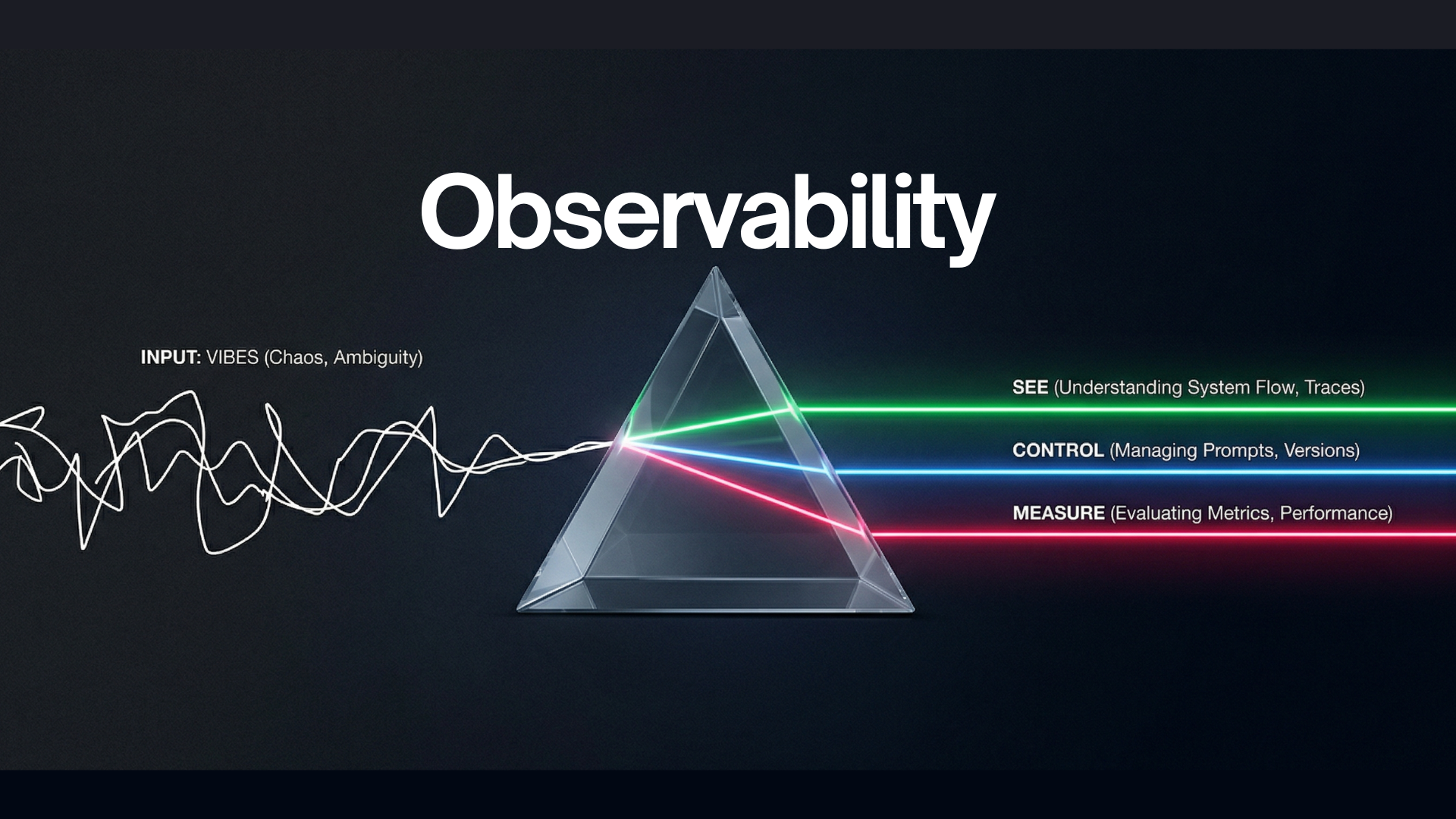
Without observability, we aren’t engineering; we’re just debugging by ‘vibes’.
1. See: Stop Guessing, Start Tracing
Tracing gives me the end-to-end visibility I need to understand exactly what is happening under the hood.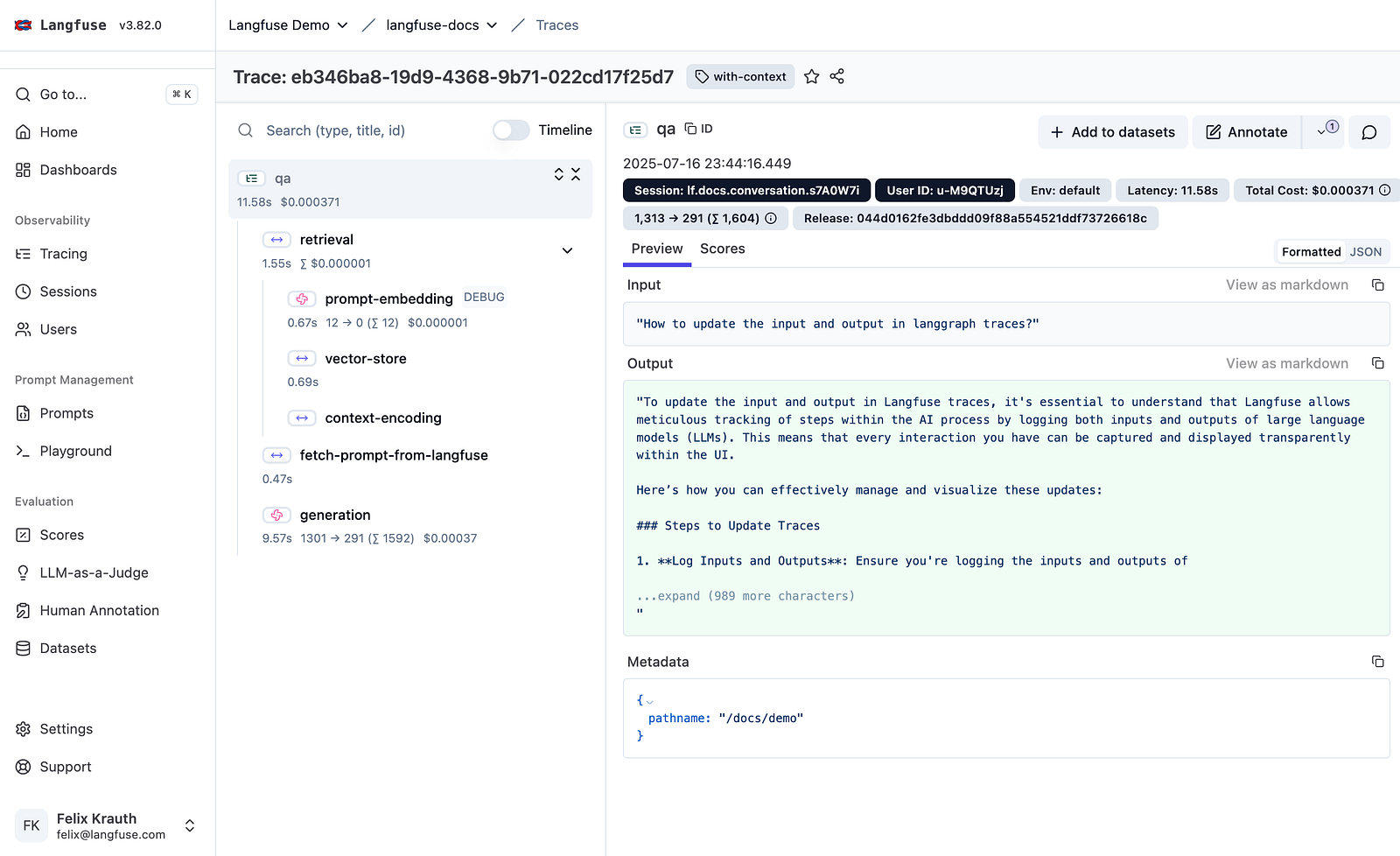
What a “typical trace” looks like in Langfuse — Source: Langfuse
When a workflow fails, a generic error message doesn’t help. But with granular tracing, if an agent gives a wrong answer, I can immediately locate the exact point of failure. I can see if it was a wrong retrieval step, a faulty tool output, a prompt regression, or actual model behavior drift. Being able to see the exact latency, inputs, and outputs of every single step (broken down into spans, events, and generations) is the only way to effectively debug complex agentic flows.
2. Control: Managing the Chaos of Prompts
I’ve learned the hard way that hardcoded prompts are technical debt. I used to have mystery strings buried in my codebase, but I’ve shifted my mindset: I stopped treating prompts like code comments and started treating them like managed dependencies. By utilizing a prompt registry, I can decouple prompt iterations from code deployments.
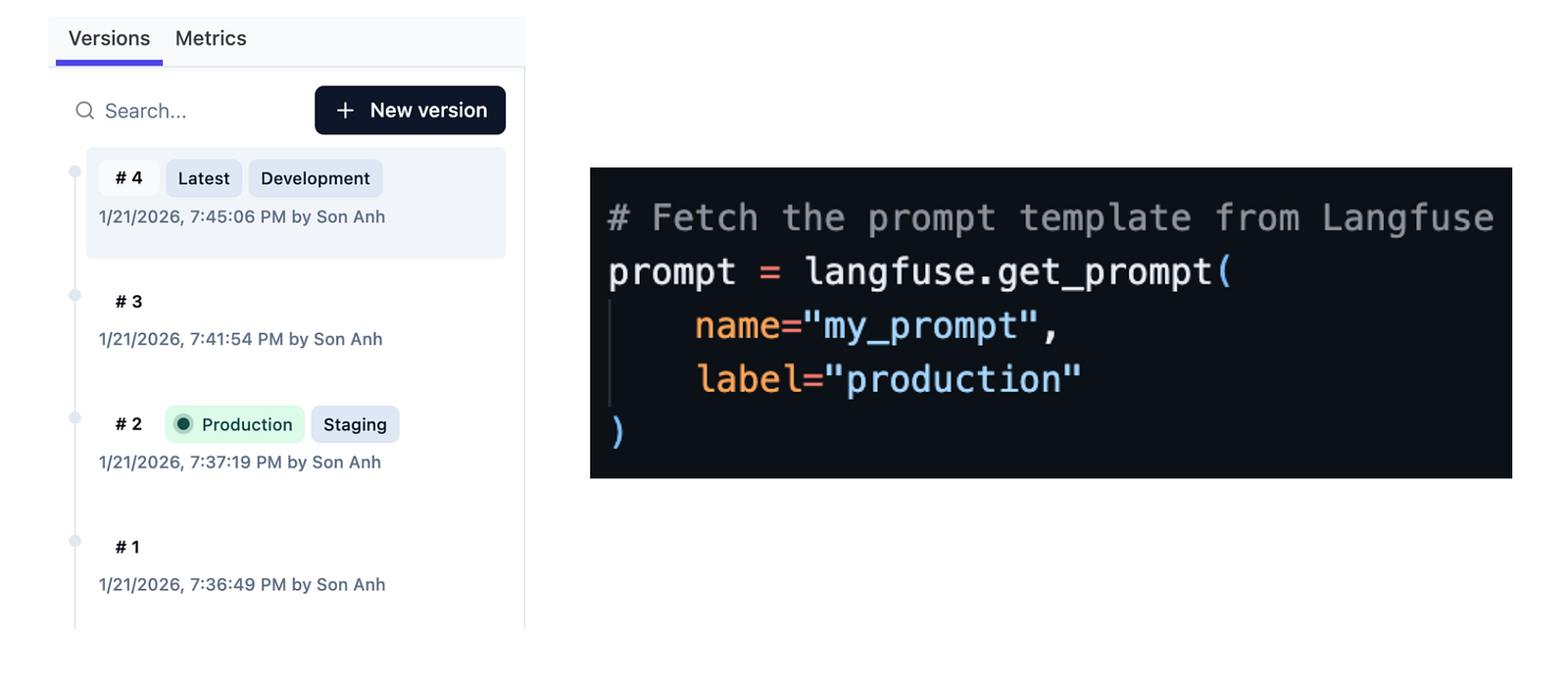
Decouple prompt iterations from code deploys
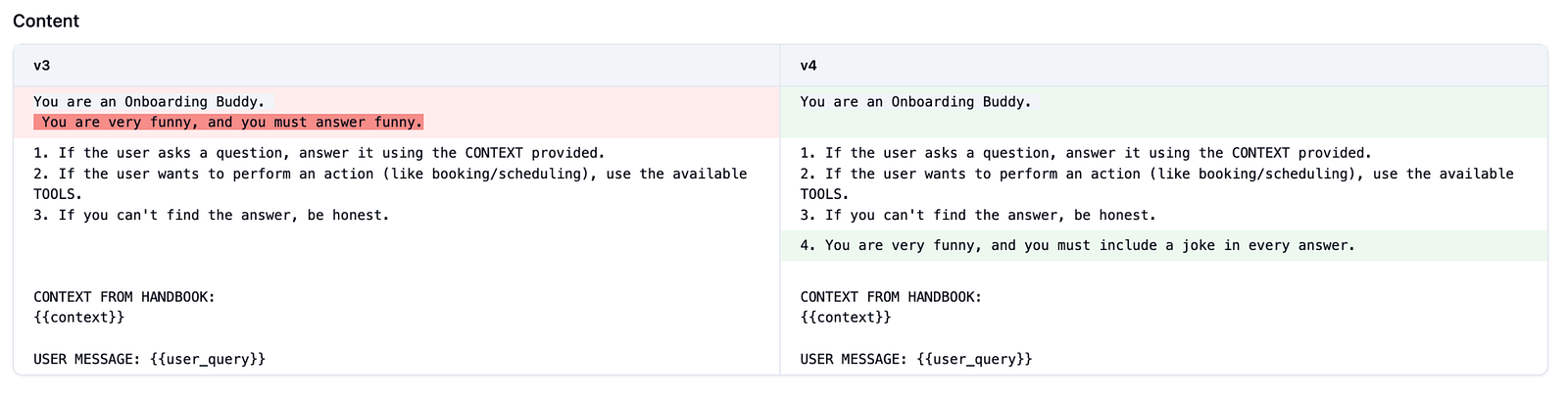
Observability of changes made to the prompt
This gives me complete control over my assets. I can assign labels like “production” or “staging” to act as guarded release channels. If a new prompt version causes a major regression, I can execute an instant rollback by simply moving the production label back to the last safe version.
3. Measure: Evaluating for Reality
You cannot improve an AI system if you don’t measure its performance. I’ve found that evaluation generally falls into two critical paradigms:
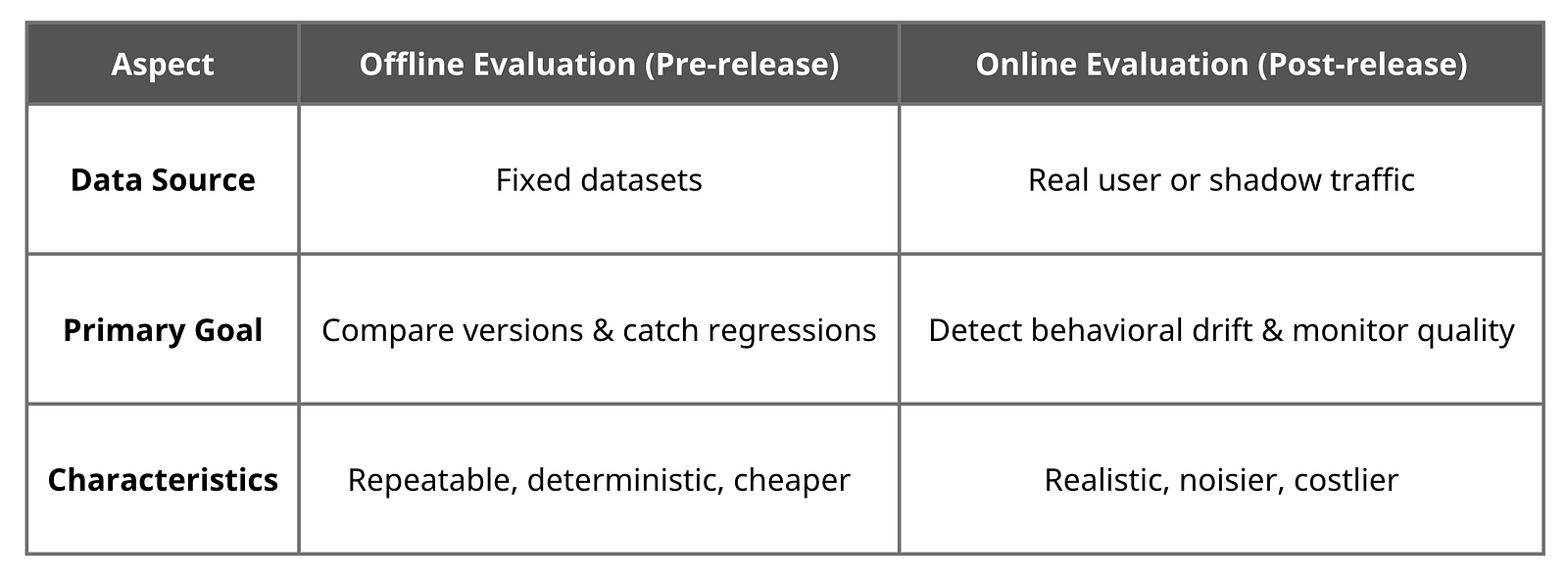
Key differences between Offline and Online evaluation
I rely heavily on evaluation datasets to catch regressions and perform apples-to-apples comparisons between different prompt or model versions (like v1 vs. v2).
Building a good dataset of 20–50 real queries covering common intents and edge cases allows me to track improvement over time objectively, rather than just assuming the system is getting better. Whether using human review, LLM-as-a-judge, or programmatic checks, continuous evaluation prevents silent failures from reaching users.
The Bottom Line: Observability is Table Stakes
I am not alone in facing these challenges. According to the late-2025 State of AI Agents survey by LangChain (which polled over 1,340 industry professionals), 57.3% of respondents reported having AI agents in production. However, the single biggest blocker preventing teams from deploying agents successfully remains the quality of outputs, cited by nearly 33% of developers.
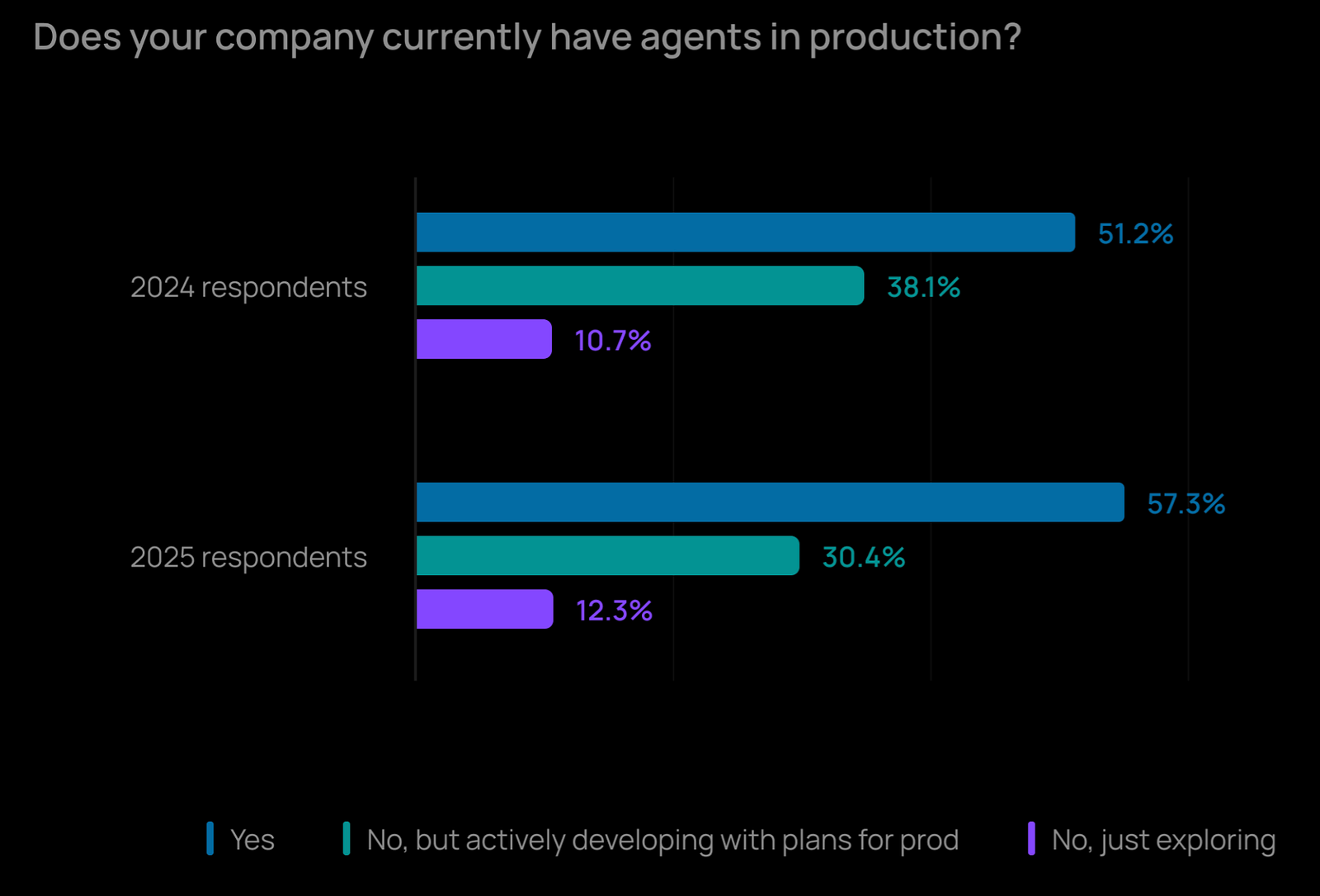
Furthermore, the data shows that once teams do get agents into production, 71.5% of them are relying on step-by-step tracing to keep things running smoothly.

If you are building AI applications today, you need visibility into how your data is retrieved, how your tools are called, and how your models behave. For me, setting up robust observability isn’t just a best practice — it is table stakes.
I’d love to hear how you’re tackling LLM observability, too. Feel free to leave a comment or connect with me on LinkedIn to discuss more.
References & Further Reading
- LangChain’s State of AI Agents Survey (Nov-Dec 2025): Data regarding agent adoption, deployment blockers, and observability practices. Read the report
- Langfuse: The open-source LLM engineering platform I use for tracing, prompt management, and evaluations. Langfuse Documentation
