
Giải đáp tất tần tật về Image Annotation
Với bài viết này, chúng tôi sẽ giải thích về các khái niệm chi tiết hơn trong Image Annotation.
Hy vọng bài viết sẽ có ích với các bạn!
Thế nào là Image Annotation?
Image Annotation là quá trình gắn nhãn hoặc phân loại một hình ảnh bằng văn bản, công cụ chú thích (hoặc cả hai) trong Machine Learning và Deep Learning. Việc chú thích này giúp hiển thị các tính năng dữ liệu mà chúng ta muốn mô hình của mình tự nhận dạng. Khi bạn chú thích một hình ảnh, bạn đang thêm siêu dữ liệu (Metadata) vào một tập dữ liệu.

(Photo by PIXTA)
Image Annotation có chức năng đánh dấu các tính năng mà bạn muốn hệ thống ML của mình nhận ra và bạn có thể sử dụng hình ảnh để đào tạo các model của mình bằng phương pháp học có giám sát (Supervised Learning). Một khi model của bạn được triển khai, bạn muốn nó có thể xác định các tính năng đó trong các hình ảnh chưa từng được chú thích và tự đưa ra quyết định hoặc thực hiện một số tác vụ.

(Photo by PIXTA)
Loại hình ảnh nào có thể được chú thích cho Machine Learning?
Hình ảnh và video, 2-D hoặc 3-D đều có thể được chú thích cho ML. Video có thể được chú thích liên tục, dưới dạng luồng hoặc theo từng khung hình.
Hình ảnh được chú thích như thế nào?
Việc chú thích hình ảnh sẽ được thực hiện thông qua các phần mềm, hay các công cụ Data Annotation. Đó có thể là phần mềm miễn phí với mã nguồn mở hoặc các bản thương mại mà bên sử dụng cần trả phí thuê hoặc mua.

(Photo by PIXTA)
Nếu dự án Data Annotation của bạn cần thực hiện trên một khối lượng dữ liệu lớn, bạn cũng sẽ cần nguồn nhân lực được đào tạo đầy đủ kỹ năng liên quan đến việc sử dụng các công cụ nêu trên để chú thích hình ảnh.

(Photo by PIXTA)
Các loại chú thích hình ảnh
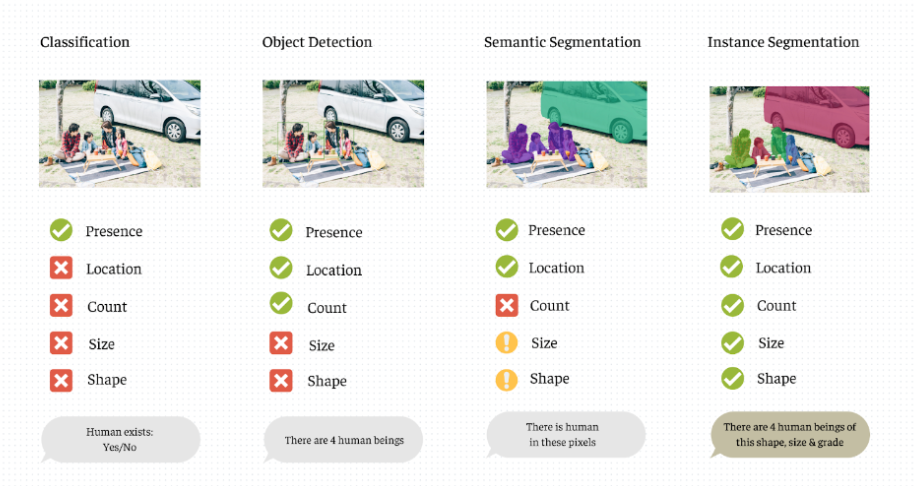 1) CLASSIFICATION (Phân loại hình ảnh)
1) CLASSIFICATION (Phân loại hình ảnh)

(Photo by PIXTA)
Chúng ta có một bức ảnh 4 người đi picnic bên cạnh 1 cái ô tô.
- Ta sử dụng Classification để xác định được hình ảnh có con người trong đó hay không.
- Tuy nhiên, vẫn chưa thể xác định được có bao nhiêu người, hình dáng họ ra sao, và họ ở vị trí nào trong không gian/hình ảnh đó.
2) OBJECT DETECTION (Nhận diện/Phát hiện đối tượng)

(Photo by PIXTA)
Với hình ảnh 4 người đi picnic, Object Detection đã bao gồm Classification, tức là:
- Đã xác định có con người trong ảnh
-
Hơn nữa còn xác định số lượng (4), vị trí của các đối tượng đó cũng như kích thước, mà ta có thể nhận biết qua các bounding box.
3) SEGMENTATION (Phân đoạn hình ảnh)
Một ứng dụng nâng cao hơn của chú thích hình ảnh là Segmentation. Phương pháp này có thể được sử dụng theo nhiều cách để phân tích nội dung trực quan trong hình ảnh nhằm xác định các đối tượng trong hình ảnh giống hay khác nhau như thế nào. Nó cũng có thể được sử dụng để xác định sự khác biệt của vật thể theo thời gian.
Có ba kiểu Segmentation:
a) Semantic Segmentation

(Photo by PIXTA)
Quay lại với với hình ảnh gia đình đi picnic ở trên, Semantic Segmentation giúp chúng ta:
- Xác định được sự xuất hiện của con người, và xe hơi trong ảnh (Classifying)
- Xác định được vị trí của con người, xe hơi trong ảnh (Localizing)
-
Nhóm các điểm ảnh đã được xác định vị trí bằng một lớp phân vùng (Segmentation)
b) Instance Segmentation

(Photo by PIXTA)
- Sự xuất hiện của con người, và xe hơi trong ảnh (Classifying)
- Vị trí của con người, xe hơi trong ảnh (Localizing)
- Nhóm các điểm ảnh đã được xác định vị trí bằng một lớp phân vùng (Segmentation)
- Số lượng, hình dạng, kích thước của từng người trong ảnh (Object Detection)
Panoptic Segmentation là sự kết hợp của Semantic Segmentation và Instance Segmentation để cung cấp dữ liệu được gắn nhãn cho cả đối tượng và bối cảnh xung quanh, cũng có nghĩa là chúng ta phân biệt được:
-
Vật thể (Things): Trong computer vision, “vật thể” là các đối tượng có hình dạng xác định, có thể đếm được, như con người, động vật, xe ô tô, bông hoa, cái cây…
-
Bối cảnh (Stuff): là những thứ không có hình dạng cụ thể, nhưng có thể xác định bằng kết cấu và chất liệu như bầu trời, con đường, nước,…
- Chụp ảnh chế độ chân dung
- Chụp ảnh chế độ xóa phông
- Chụp ảnh tự động lấy nét…
Kết luận
Với các định nghĩa cơ bản và một số hình ảnh minh hoạ trực quan, hy vọng sau bài viết này đã giúp các bạn hiểu rõ Image Annotation là gì và các phương pháp Image Annotation hiện đang được sử dụng trong ML và AI.
Hẹn gặp lại các bạn vào các bài viết sau!
Tác giả: Cao Minh Ngọc
Tìm hiểu thêm về cơ hội làm việc tại Pixta Vietnam tại đây
🌐 Website: https://pixta.vn/careers
🏠 Facebook: https://www.facebook.com/pixtaVN
🔖 LinkedIn: https://www.linkedin.com/company/pixta-vietnam/
✉️ Email: recruit.vn@pixta.co.jp
☎️ Hotline: 024.6664.1988
