
Tổng quan về Database, SQL và NoSQL
Từ lâu, con người đã dùng những phương pháp thô sơ như khắc lên đá, ghi chép sổ sách,.. cho đến băng đĩa cassette, đĩa mềm,.. để ghi chép lại dữ liệu. Cơ sở dữ liệu có ở khắp mọi nơi và được sử dụng để nâng cao cuộc sống hàng ngày của chúng ta. Từ lưu trữ đám mây cho đến thương mại điện tử, nhiều dịch vụ chúng ta sử dụng ngày nay đều có thể thực hiện được nhờ có cơ sở dữ liệu. Cùng tìm hiểu về các loại cơ sở dữ liệu phổ biến hiện nay và tính ứng dụng của chúng tại đây.
Phân loại cơ sở dữ liệu
Cơ sở dữ liệu (Database) là một tập hợp dữ liệu có tổ chức được lưu trữ và truy cập điện tử. Các kỹ luật liên quan đến Database mà ta thường gặp bao gồm :
- Mô hình hóa dữ liệu
- Lưu trữ dữ liệu hiệu quả
- Ngôn ngữ truy vấn
- Bảo mật
- Tính toán phân tán – bao gồm hỗ trợ truy cập đồng thời và khả năng chịu lỗi.
Các công nghệ cơ sở dữ liệu từ khi hình thành cho đến nay đã trải qua nhiều thế hệ với nhiều hình thái khác nhau nhằm mục đích cung cấp một cách phù hợp và hiệu quả để lưu trữ và truy cập dữ liệu liên tục thông qua việc phát triển các hệ thống quản lý.
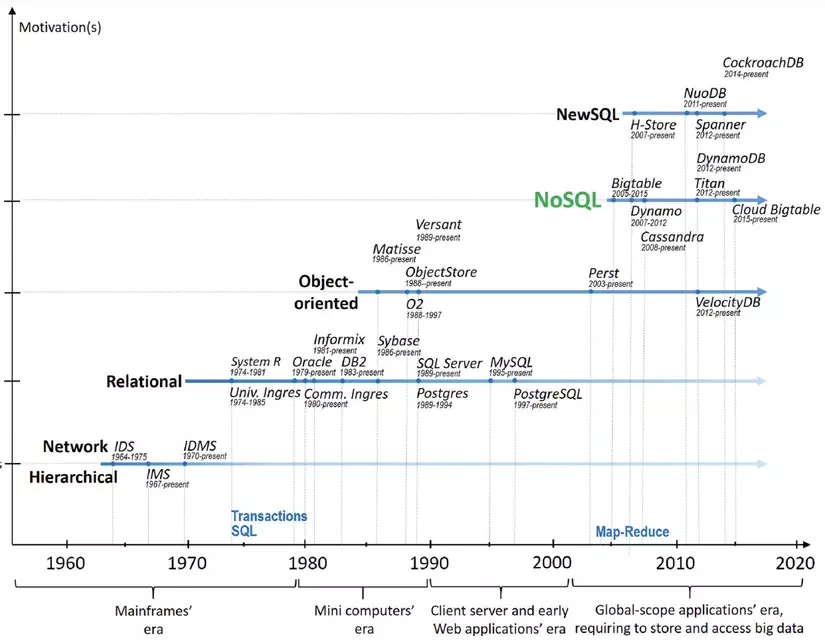
Ngày nay, hai phân hệ hệ quản trị cơ sở dữ liệu phổ biến nhất được dùng vẫn là:
Cơ sở dữ liệu quan hệ (SQL)
Cơ sở dữ liệu quan hệ, còn được gọi là cơ sở dữ liệu SQL, là hệ thống lưu trữ dữ liệu theo dạng bảng và hàng (còn được gọi là các bản ghi). Trong mỗi bảng lưu trữ thông tin về một đối tượng và giá trị các thuộc tính của chúng. Chẳng hạn dưới đây ta có ví dụ về lưu trữ thông tin khách hàng sản phẩm và lịch sử mua hàng.
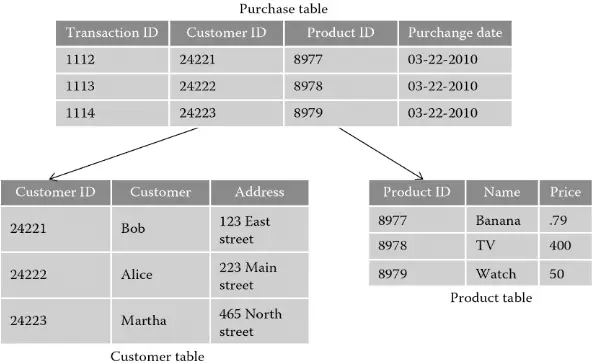
-
Bảng (Tables): Dữ liệu được cấu trúc dưới dạng các bảng chứa thông tin, một cơ sở dữ liệu thường gồm nhiều bảng tạo nên một lược đồ quan hệ (relational schema).
-
Bản ghi (Records/Rows): Các hàng của bảng trong cơ sở dữ liệu, tương ứng với một đối tượng và chứa thông tin về đối tượng cần lưu trữ đó
-
Trường thuộc tính (Columns/Fields): Đặc điểm của đối tượng được lưu trữ trong csdl, ví dụ đối với thông tin khách hàng, ta cần các trường thuộc tính như tên, địa chỉ,…
-
Khóa (Keys): Khóa là một trường (field) đặc biệt, chúng tạo ra mối quan hệ giữa các bảng với nhau
- Khóa chính (Primary key): Trong mỗi bảng có một trường khóa chính và có giá trị duy nhất cho mỗi bản ghi, mang ý nghĩa định danh cho bản ghi đó.
- Khóa ngoại (Foreign keys): là một trường trong một bảng trỏ đến trường khóa chính của bảng khác, có tác dụng liên kết các bảng.
-
Quan hệ (Relationals): Mô tả cách các bảng liên kết qua khóa và chia sẻ thông tin.
- One-to-one: từng bản ghi trong bảng này đều tương ứng chính xác với bản ghi trong bảng kia. Vd: một người chỉ có 1 căn cước công dân duy nhất.
- One-to-many: mỗi bản ghi trong bảng có thể liên kết với nhiều bản ghi trong bảng khác. Vd: Một người có thể có nhiều địa chỉ nhà
- Many-to-many: tương tự như one-to-many nhưng là hai chiều. Vd: một người có thể có nhiều địa chỉ và ngược lại trong một địa chỉ có thể có nhiều người sinh sống.
-
Lược đồ csdl (Database Schema): bản thiết kế cho cơ sở dữ liệu, mô tả cách ta sẽ lưu trữ thông tin và thông tin đó sẽ liên quan đến nhau như thế nào. Bao gồm quy tắc cho các trường, mối quan hệ các bảng, …
-
Chỉ mục (Indexes): lập chỉ mục cho một hoặc nhiều trường giúp tìm kiếm trong csdl trở nên dễ dàng và nhanh hơn.
Ngoài ra, cơ sở dữ liệu quan hệ nổi tiếng với khả năng xử lý giao dịch, đảm bảo 4 thuộc tính ACID (atomicity, consistency, isolation, và durability) dưới đây.
| Attribute | Function | Description |
|---|---|---|
| Atomicity | Transaction Manager | Giao dịch gồm nhiều thao tác chỉ thành công khi toàn bộ thao tác thành công |
| Consistency | Application programmer | Dữ liệu cần trở lại trạng thái trước khi giao dịch nếu gặp lỗi (rollback) |
| Isolation | Concurrency Control Manager | Thực thi các giao dịch độc lập với nhau một cách đồng thời |
| Durability | Recovery Manager | Đảm bảo dữ liệu giao dịch được lưu trữ trong cả trường hợp lỗi hệ thống |
Các cơ sở dữ liệu quan hệ phổ biến nhất hiện nay là Microsoft SQL Server, Oracle Database, MySQL và IBM DB2. Một số phiên bản miễn phí của các nền tảng RDBMS này đã trở nên phổ biến trong những năm qua, chẳng hạn như SQL Server Express, PostgreSQL, SQLite, MySQL và MariaDB.
Ưu điểm:
- Hoạt động với dữ liệu có cấu trúc, được định hướng bảng và hàng nên rất trực quan
- Các mối quan hệ trong hệ thống có những ràng buộc, điều này thúc đẩy mức độ toàn vẹn dữ liệu cao.
- Cung cấp khả năng viết các truy vấn SQL (ngôn ngữ truy vấn có cấu trúc) phức tạp để thao tác dữ liệu, phân tích và báo cáo dữ liệu một cách mạnh mẽ
Nhược điểm:
- Một nhược điểm lớn ta dễ dàng có thể thấy đó là khó sửa đổi, mở rộng do số lượng kết nối ngày một tăng cao.
- Cần phải định nghĩa trước về cấu trúc dữ liệu trước khi thêm dữ liệu vào.
Cơ sở dữ liệu phi quan hệ (NoSQL)
Trên thực tế, các hệ thống phần chúng ta xây dựng không nhất thiết yêu cầu dữ liệu có quan hệ. Không phải mọi phần mềm đều yêu cầu tính nhất quán, chính xác trong các giao dịch hay truy vấn phức tạp. Điển hình là Facebook Messenger, nơi chúng ta hy vọng có thể nhắn tin 24/24 với nhiều người truy cập hơn là các giao dịch chính xác. Facebook cũng hiểu được điều đó nên đã xây dựng Cassandra, một trong những opensource NoSQL-Database nổi tiếng sau này được Apache cấp phép.

Nhiều cơ sở dữ liệu NoSQL hy sinh tính nhất quán (đề cập trong định lý CAP) để ưu tiên cho tính sẵn sàng, dung lượng của phân vùng, và tốc độ truy cập.
Có 4 loại Nosql-Database phổ biến:
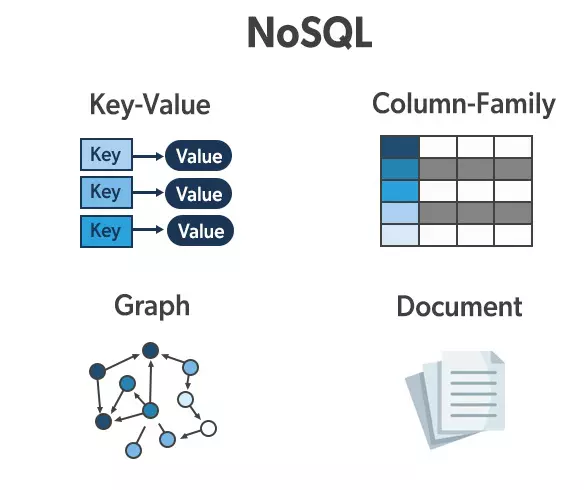
1. Column:
Cũng như tên gọi của nó, dữ liệu trong database được lưu dưới dạng các cột thay vì các hàng.
Lấy cảm hứng từ Google Bigtable, dữ liệu được tổ chức dưới dạng các cột, phân tách theo giá trị của một hoặc nhiều thuộc tính nào đó. Mỗi column thường chỉ có các trường Name, Value, TimeStamp
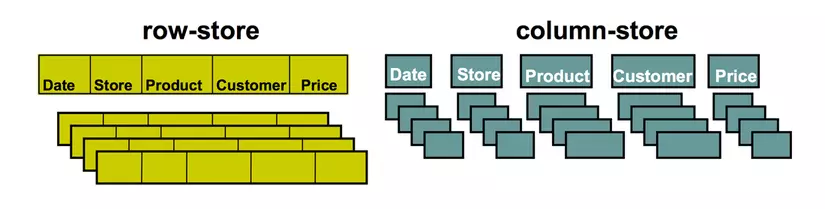
Column-DBMS sử dụng không gian khóa giống như lược đồ cơ sở dữ liệu trong RDBMS do đó có thể được coi là bán quan hệ (semi-realtional database). Mỗi khóa được sử dụng để lưu trữ metadata cho các column-family. Column-family có thể được coi giống như một bảng trong RDBMS, bao gồm họ các column liên quan tới nhau. Ví dụ dưới đây cho thấy sự tương đương giữa bẳng AuthorProfile và column-family của nó.
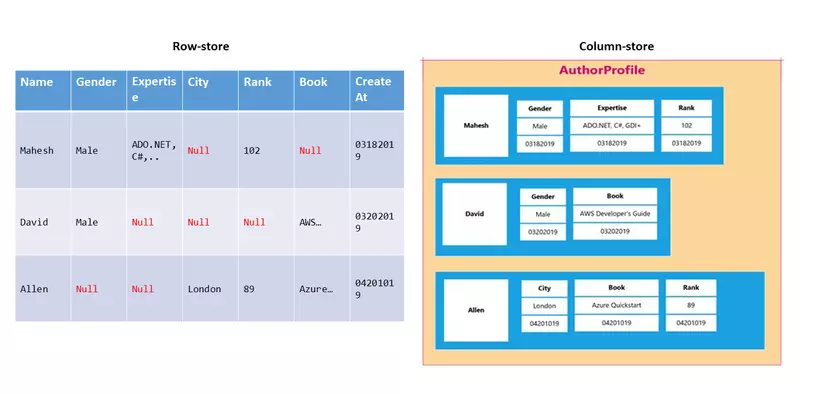
null, dẫn đến tốn không gian lưu trữ. Ngoài ra, khi truy vấn sẽ tách thành các truy vấn trên cột, đem lại hiệu suất nhanh hơn trong các chức năng query, tìm kiếm và tổng hợp.Cơ sở dữ liệu dạng cột được dùng trong trường lưu trữ dữ liệu lớn, thao tác đọc nhiều hơn là ghi dữ liệu.
Các cơ sở dữ liệu nổi tiếng dựa trên Column: Cassandra, HBase, Vertica
2. Key-value:
Dữ liệu đơn giản được lưu trữ dưới dạng (key,value), giá dữ liệu có thể không cùng loại với nhau. Về tốc độc truy vấn vô cùng nhanh và có khả năng mở rộng cao.
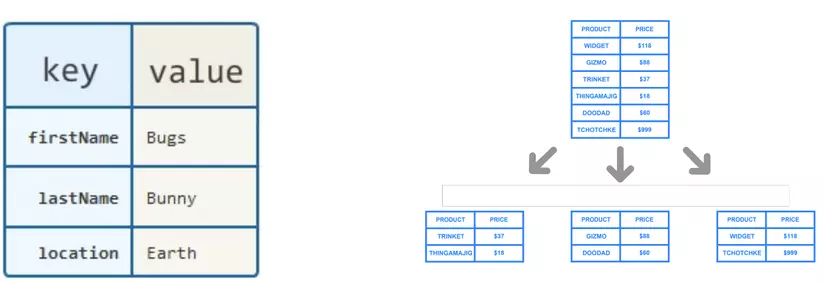
Các cơ sở dữ liệu key-value điển hình: CouchDB, Dynamo, Redis, Riak, Berkeley DB
3. Document:
Là một phần mở rộng của Key-Value, nơi các giá trị được lưu trữ trong các document có cấu trúc như XML hoặc JSON. Document giúp bạn dễ dàng ánh xạ các đối tượng trong hướng đối tượng sang database.
Cơ sở dữ liệu document không có lược đồ cố định, bạn không cần phải xác định trước lược đồ và tuân thủ nó. Nó cho phép ta lưu trữ dữ liệu phức tạp ở các định dạng document (JSON, XML, v.v.) một cách rất linh hoạt.

Một số Document Database thường thấy hiện nay: Apache CouchDB, DocumentDB, MongoDB, OrientDB, Elasticsearch
4. Graph:
Các mô hình dữ liệu phi quan hệ kể trên lưu trữ thông tin về các thực thể như các giá trị key-value, hàng trong các bảng nhiều cột hoặc tài liệu. Tuy nhiên, số lượng ngày càng tăng của các bộ dữ liệu có liên kết định hướng đồ thị, chẳng hạn như Semantic Web, Web Mining đã tạo ra nhu cầu về các mối quan hệ thực thể một cách hiệu quả. Điều này đã thúc đẩy sự xuất hiện của các cơ sở dữ liệu đồ thị để lưu trữ các bộ dữ liệu này một cách hiệu quả và cung cấp các hoạt động hiệu quả cho truy vấn và phân tích.
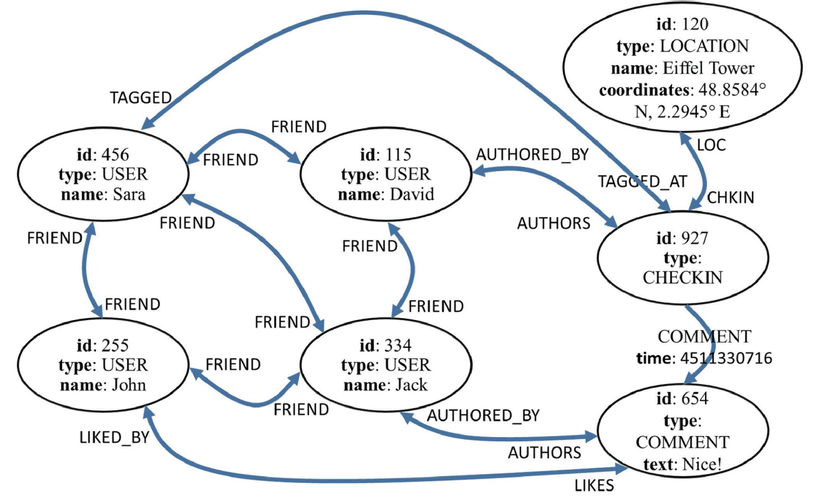
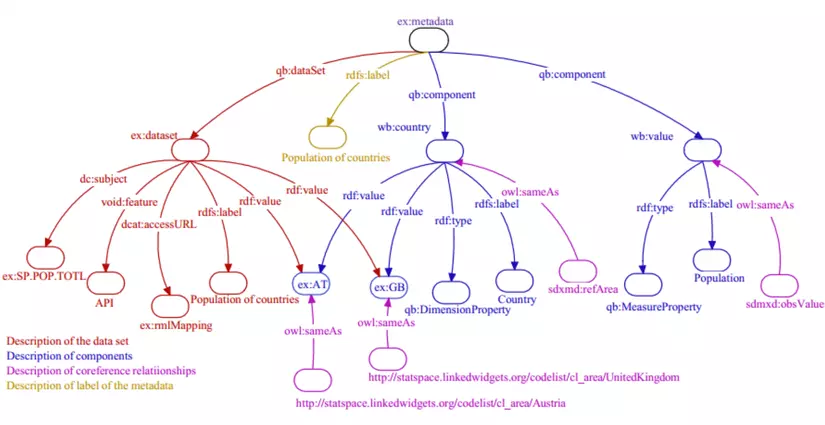
Các csdl này dựa trên nền tảng lý thuyết đồ thị mạnh mẽ, trong đó biểu đồ bao gồm các đỉnh đại diện cho các thực thể và các cạnh đại diện cho mối quan hệ giữa chúng. Có nhiều cách để xây dựng graph-database như dựa trên đồ thị vô hướng, đồ thị gắn nhãn hay đồ thị thuộc tính,… dưới đây là một ví dụ trong biểu diễn Web sematic bằng chuẩn RDF. Các mối quan hệ được thể hệ qua các bộ ba (Subject, Predicate, Object) và được mapping bởi ngôn ngữ RML mỗi khi truy vấn qua URL.
Ưu điểm:
- Available: Dữ liệu thường được phân tán trên một số máy chủ và khu vực, do đó ổn định và linh hoạt hơn.
- Performance: NoSQL đem lại hiệu suất truy vấn tuyệt vời trên cả thông lượng và độ trễ.
- Scalability: Các csdl phi quan hệ có khả năng mở rộng một cách linh hoạt và được scale theo chiều ngang thay vì theo chiều dọc, điều này mang lại lợi thế rõ ràng so với cơ sở dữ liệu SQL.
- Flexible: Kiểu dữ liệu không được cấu trúc và định nghĩa trước giúp ta linh hoạt trong quá trình phát triển hệ thống.
- Data models: các mô hình dữ liệu đa dạng, có xu hướng cực kỳ chuyên biệt trong các trường hợp sử dụng cụ thể, cho phép chúng hoạt động tốt hơn cơ sở dữ liệu quan hệ.
Nhược điểm:
- Chưa hỗ trợ tốt các giao dịch trên nhiều tài liệu. Điển hình như tính nhất quán (Consistency – “C” in ACID) sẽ cần được trade-off với tính Available và Performance như đã đề cập trong định lý CAP.
- Không hiệu quả đối với những truy vấn phức tạp cần sử dụng nhiều liên kết.
- Chưa hoàn thiện: Các mô hình quan hệ đã xuất hiện được một thời gian so với các mô hình NoSQL và kết quả là chúng đã phát triển thành các hệ thống ổn định và có nhiều chức năng hơn trong những năm qua.
SQL vs NoSQL
| SQL | NoSQL |
|---|---|
| Dữ liệu vài Gigabytes tới Terabytes | Dữ liệu từ Petabytes(1kTB) tới Exabytes(1kPB), Zetabytes(1kEB) |
| Tập trung | Phân tán |
| Có cấu trúc | Bán cấu trúc hoặc không có cấu trúc |
| Structured Query Language | No declarative query language |
| Complex Relationships | Less complex relationships |
| ACID Property | Eventual Consistency |
| Ưu tiên transaction | Ưu tiên tính khả dụng, mở rộng |
| Joins Tables | Embedded structures |
Tổng kết
Cũng giống như sự khởi đầu của lịch sử cơ sở dữ liệu và quản lý cơ sở dữ liệu, tương lai sẽ gắn liền với sự phát triển tổng thể trong việc xử lý và tính toán trên dữ liệu. Học máy và trí tuệ nhân tạo sẽ tiếp tục cải thiện và trở thành một phần không thể thiếu trong cơ sở dữ liệu và quản trị cơ sở dữ liệu. Các công cụ quản lý cơ sở dữ liệu ngày càng nhanh hơn và hiệu quả hơn sẽ được xây dựng và phát triển kế thừa trên các chuẩn cũ. Cuối cùng, tương lai có vẻ vô cùng tươi sáng cho ngành cơ sở dữ liệu. ⭐
Mong rằng qua bài viết này có thể giúp các bạn dễ hình dung hơn về các hệ quản trị cơ sở dữ liệu và tính ứng dụng của chúng. Trong các phần tiếp theo mình sẽ tiếp tục nói về các thành phần và kỹ thuật trong Database nếu các bạn quan tâm hãy đón đọc nhé.
Tham khảo
- https://en.wikipedia.org/wiki/Database
- https://blog.airtable.com/what-is-a-relational-database/
- Davoudian, A., Chen, L., & Liu, M. (2018). A survey on NoSQL stores. ACM Computing Surveys (CSUR), 51(2), 1-43.
- https://www.quickbase.com/articles/timeline-of-database-history
- https://database.guide/what-is-a-column-store-database/
Tìm hiểu thêm về Pixta Vietnam
🌐 Website: https://pixta.vn/careers
🏠 Fanpage: https://www.facebook.com/pixtaVN
🔖 LinkedIn: https://www.linkedin.com/company/pixta-vietnam/
