
Làm chủ không gian với InstanceDiffusion: Định nghĩa lại sự tự do cho các mô hình sinh ảnh?
Giới thiệu
Những text-to-image diffusion model hiện có gặp khó khăn trong việc sinh ra hình ảnh theo điều kiện/dense caption, mà ở đó text prompt mô tả chi tiết vật thể nào ở vị trí nào.
Đó là lý do mà cũng đã có 1 số lượng tương đối các nhà nghiên cứu cho ra mắt các layout+text-to-image diffusion model, nổi bật như SpaText, GLIGEN, ControlNet và DenseDiffusion… Tuy nhiên tất cả những model đó đều chỉ tận dụng một kiểu layout (hoặc là bounding boxes, hoặc là mask) trong 1 lần inference. Các bạn có thể kiểm tra ở mục tham khảo.
Câu hỏi đặt ra là liệu có phương pháp hay model nào không bị hạn chế bởi định dạng layout, và thực sự chạm đến tự do không? Câu trả lời nằm ở InstanceDiffusion – SOTA – CVPR 2024.
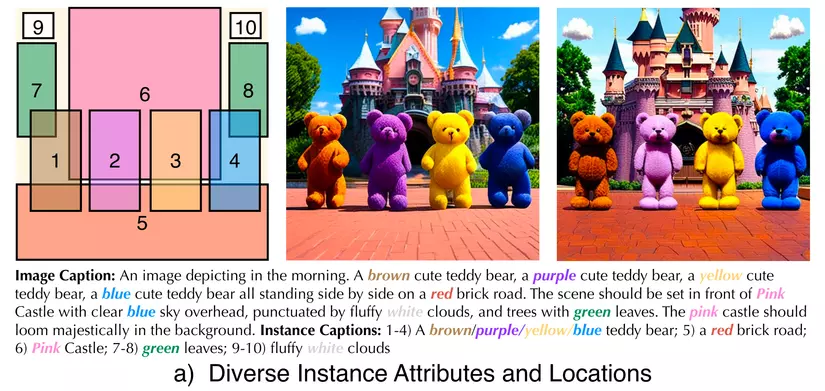
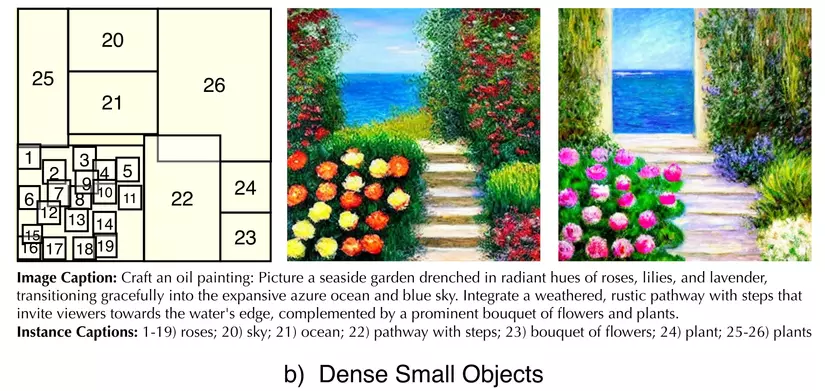


Fig 1: Khả năng của InstanceDiffusion
Xác định vấn đề
Tác giả cải thiện khả năng sinh ảnh theo điều kiện bằng cách tận dụng cả hai loại thông tin, text và location. Có thể viết model của ở dạng f(cg, {(c1, l1), …, (cn, ln)}) với input là global text caption cg và (caption ci , location li )(ci, li) cho n điều kiện.
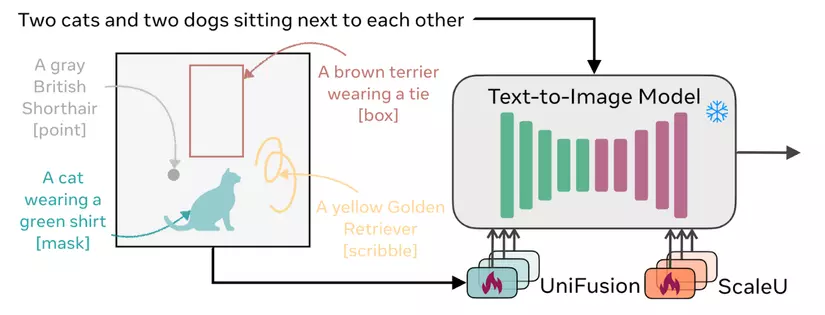
Fig 2: Kiến trúc của InstanceDiffusion, backbone Unet trong Stable Diffusion v1-5
UniFusion
Lý do: Chắc chắn trong bài toán này, chúng ta nhất định phải có cách để chiếu các thông tin khác nhau về cùng một không gian và kết hợp chúng lại. UniFusion sẽ giúp chúng ta xử lý điều đó một cách hiệu quả.
UniFusion chiếu các loại điều kiện có định dạng khác nhau về cùng một không gian, đồng thời, tích hợp thông tin về location, caption với thông tin visual từ diffusion backbone.
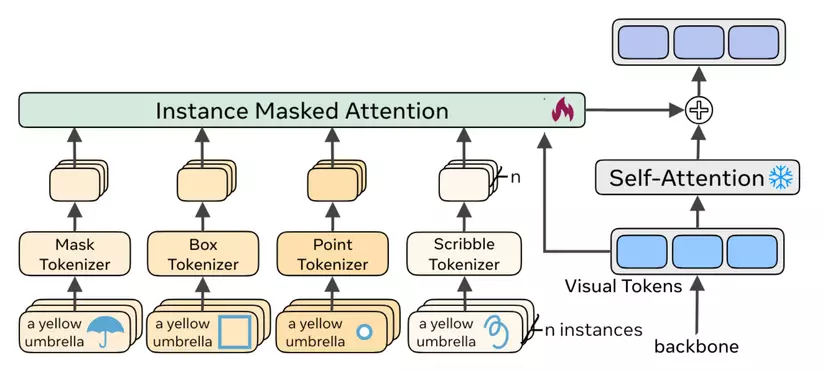
Fig 3: Kiến trúc UniFusion
Một điều cần chú ý nữa là UniFusion được tích hợp giữa 2 lớp self-attention và cross-attention.
1. Tham số hóa vị trí cho các điều kiện khác nhau (Location parameterization)
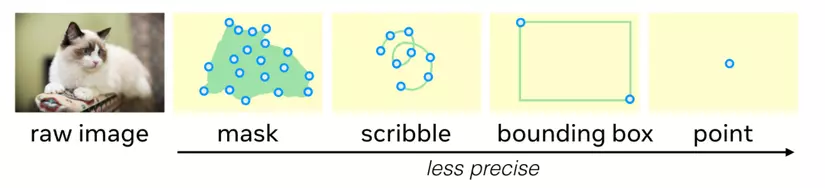
Fig 4: Location parameterization
Tác giả chuyển đổi:
- Instance masks —> một tập hợp các điểm trong mask.
- Nét viết (scribble) —> Một tập hợp các điểm đều nhau.
- Bounding boxes —> Điểm trên cùng bên trái và dưới cùng bên phải.
2. Mã hóa điều kiện (Instance Tokenizer)
Tác giả chuyển đổi tọa độ điểm 2D pi cho các vị trí sử dụng Fourier mapping γ(·) và mã hóa caption ci sử dụng bộ CLIP text encoder τθ(·).
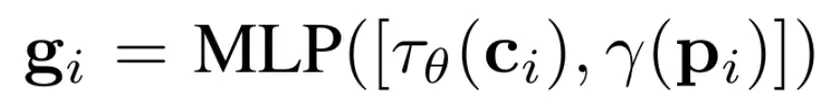
Với mỗi định dạng điều kiện, tác giả dùng mạng MLP khác nhau, vì thế với 1 điều kiện i, chúng ta có gscribblei, gboxi, gpointi, and gmaski.
Tuy nhiên nếu 1 điều kiện được thể hiện bởi 1 định dạng, tác giả sẽ dùng learnable null token ei cho những định dạng còn lại.
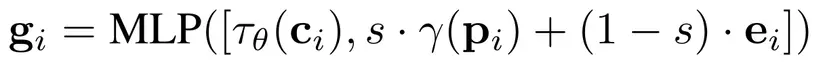
s là giá trị nhị phân thể hiện sự xuất hiện của 1 định dạng cụ thể.
3. Instance-Masked Attention và cơ chế kết hợp
Tác giả biểu thị các instance condition tokens cho từng vị trí nhưng cùng thuộc 1 định dạng là g, cho tất cả vị trí là G, và từng visual tokens là v, tất cả là V.
Tác giả quan sát thấy rằng vanilla self-attention dẫn tới việc rò rỉ thông tin của các điều kiện, (màu sắc của điều kiện này lại được thể hiện bởi điều kiện khác). Vì thế họ xây dựng mask M giúp tránh việc rò rỉ thông tin, việc này cũng khá tương tự với cơ chế masked attention của transformer.
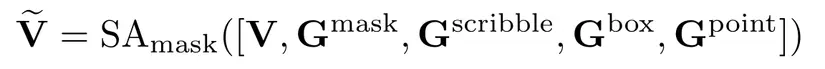
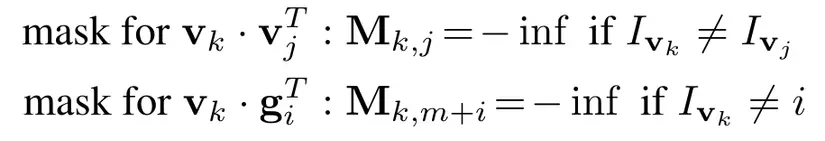
Ivk = i nếu visual tokens vk thuộc cùng 1 vị trí với điều kiện i.
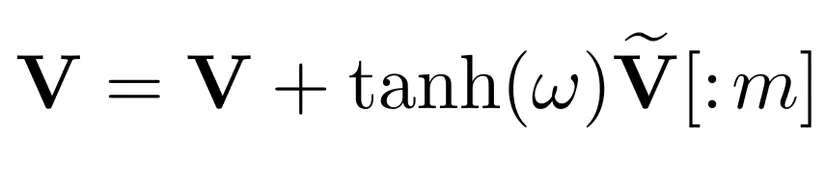
w là learnable parameter, khởi tạo bằng 0, mục đích là điều khiển tầm ảnh hưởng của điều kiện.
ScaleU
ScaleU giúp tinh chỉnh skip connection của UNet, có 2 learnable scaling vector: 𝑆𝑏 cho feature chính và 𝑆𝑠 cho skip-connected features.
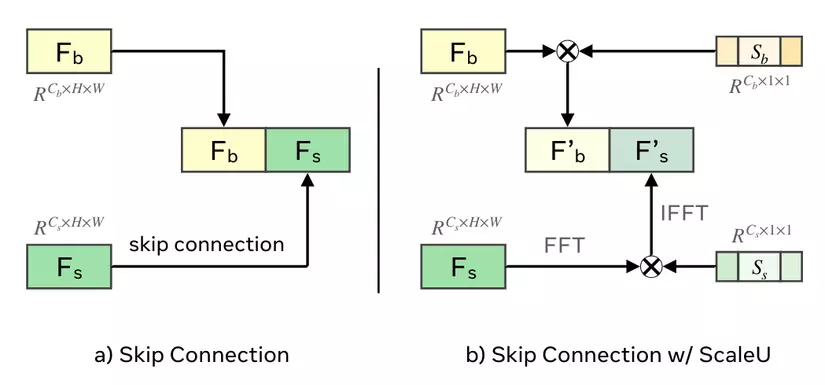
Fig 5: Skip Connection
𝐹𝑏 được scaled bởi một phép nhân theo channel:
𝐹𝑏′=𝐹𝑏⊗(tanh(𝑆𝑏)+1).
Đối với skip-connection features, họ chọn ra những feature có tần số xuất hiện thấp (ít hơn 𝑟thresh) sử dụng frequency mask 𝛼 và scale chúng trong Fourier domain:
𝐹𝑠′=IFFT(FFT(𝐹𝑠)⊙𝛼).
FFT(.) là phép biến đổi Fast-Fourier và IFFT(.) là phép biến đổi Inverse-Fast-Fourier , ⊙ là phép nhân theo phần tử, và
𝛼(𝑟)=tanh(𝑆𝑠)+1 if 𝑟<𝑟thresh otherwise =1,
𝑟 biểu thị tần số, và 𝑟thresh là một ngưỡng. 𝑆𝑏 và 𝑆𝑠 đều được khởi tạo là vectors 0.
Multi-instance Sampler cho quá trình Inference
Tác giả cũng giới thiệu một cách nữa để tránh rò rỉ thông tin, đó là chiến lược Multi-instance Sampler trong khi inference.
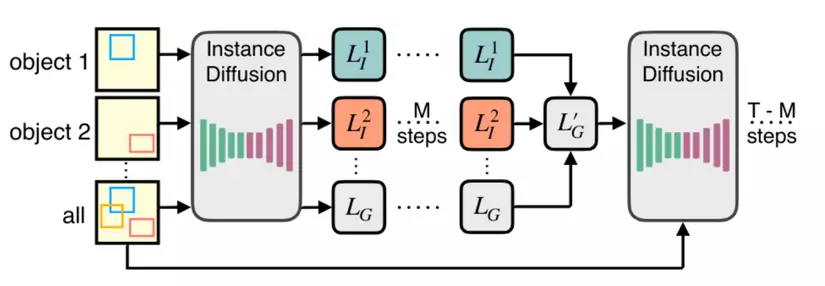
Fig 6: InstanceDiffusion trong quá trình inference
- Với mỗi 𝑛 điều kiện, chúng ta sẽ có sự khử nhiễu riêng biệt trong 𝑀 bước (ít hơn 10% của tổng số bước) để có được** latent instance embedding **𝐿𝑖.
- Kết hợp denoised instance latents {𝐿1,…,𝐿𝑛} với global latent 𝐿𝐺 bằng việc tính trung bình tất cả latents.
- Khử nhiễu với đầu vào là aggregated latent từ bước (2) trong T-M bước, tận dụng tất cả instance tokens và text prompts.
Chuẩn bị dữ liệu với Instance Captions
Có được một dataset với domain lớn cho bài toán này là rất khó. Vậy nên để có được nhiều thông tin chi tiết về điều kiện (diều hâu) và đặc trưng của điều kiện (mắt của diều hâu), tác giả xây dựng bộ dữ liệu dựa vào nhiều model.
- Image-level label generation: Tác giả dùng RAM, một model gắn thẻ (tagging) hình ảnh mạnh mẽ với vốn từ vựng mở, để tạo ra danh sách những thẻ (tag) cho hình ảnh.
- Bounding-box and mask generation: Tác giả dùng Grounded-SAM để có được bounding boxes và masks tương ứng với những thẻ. Các thẻ này có thể ở mức độ điều kiện hoặc đặc trưng của điều kiện.
- Instance-level text prompt generation: Để sinh ra văn bản có thể mô tả từng điều kiện, họ cắt điều kiện dựa vào tọa bộ bounding boxes và tạo ra captions cho những ảnh cắt đó sử dụng Vision-Language Model BLIP-V2.
Evaluation metrics
Dưới đây là phương pháp mà họ dùng để đo độ chính xác mà vật thể được tạo ta gắn với những định dạng location khác nhau
Bounding box:
- So sánh bounding boxes mà model phát hiện được trên generated image với bounding boxes có sẵn từ input sử dụng phương pháp đánh giá chính thức của COCO (AP và AR).
Instance mask:
- So sánh predicted mask trên generated image dùng YOLOv8m-Seg với masks có sẵn từ đầu vào bằng chỉ số IOU.
Scribble:
- Do trước đây chưa xuất hiện phương pháp đánh giá cho Scribble nên họ đề xuất một chỉ số đánh giá mới sử dụng YOLOv8m-Seg. Đó là “Points in Mask” (PiM), đo lường có bao nhiêu điểm ngẫu nhiên trên input scribble nằm trong predicted mask.
Single-point:
- Giống với scribble, độ chính xác của PiM là 1 nếu điểm này nằm trong predicted mask, 0 cho trường hợp còn lại. Sau đó họ tính trung bình điểm PiM.
So sánh với các model khác
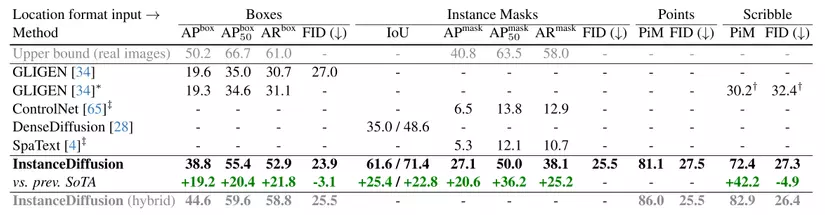
Fig 7: So sánh InstanceDiffusion có kết quả ấn tượng nhất ở tất cả các định dạng
8. Một vài hình ảnh minh hoạ

Fig 8: InstanceDiffusion với nhiều định dạng điều kiện

Fig 9: Iterative Image Generation
Kết luận
Còn một vài kĩ thuật, thiết kế nữa cũng rất hay nhưng mình không nêu ở đây vì đó là gợi ý của tác giả. Các bạn có thể đọc thêm tại paper gốc nhé, mình sẽ gắn link ở phần tham khảo. Xin cảm ơn và hẹn gặp lại các bạn trong những bài tiếp theo.
Tham khảo
- GliGen: https://gligen.github.io/
- SpaText: https://omriavrahami.com/spatext/
- DenseDiffusion: https://arxiv.org/pdf/2308.12964
- InstanceDiffusion: https://arxiv.org/pdf/2402.03290
Tác giả: Nguyễn Minh Đức
