
YOLOv2 – tốt hơn, nhanh hơn và mạnh mẽ hơn
1. Giới thiệu
Đúng như tiêu đề ấn tượng của bài báo: “YOLO9000: Better, Faster, Stronger“, YOLOv2 kế thừa và phát triển tiếp từ YOLOv1 với hàng loạt những sự thay đổi và cải tiến mới để cho ra một phiên bản nâng cấp vừa tốt hơn, nhanh hơn, và còn mạnh mẽ hơn. Những thay đổi này bao gồm việc tận dụng lại các công trình làm việc trước đó, đồng thời sáng tạo ra các phương pháp mới. Mô hình cải tiến YOLOv2 đạt được kết quả SOTA các tập dữ liệu PASCAL VOC và COCO, vượt trội hơn hẳn các phương pháp khác như Faster R-CNN + ResNet và SSD trong khi tốc độ vẫn nhanh hơn nhiều:
* Tại tốc độ 67 FPS, YOLOv2 có độ chính xác 76.8 mAP trên tập dữ liệu test VOC 2007.
* Tại tốc độ 40 FPS, YOLOv2 có độ chính xác 78.6 mAP.

Tiếp theo, các tác giả đề xuất một phương pháp huấn luyện YOLOv2 đồng thời trên tập dữ liệu detection và classification. Với phương pháp này, mô hình được train đồng thời trên các tập dữ liệu COCO (detection) và ImageNet (classification), từ đó cho ra phiên bản YOLO9000 với khả năng detect hơn 9000 đối tượng khác nhau, tất cả đều trong thời gian thực.
2. Chi tiết thuật toán
2.1. Tốt hơn
Nhắc lại rằng, YOLOv1 có một số nhược điểm so với các hệ thống detection hàng đầu ở thời điểm đó:
- YOLO có Localization Errors khá cao – nó gặp khó khăn trong việc định vị vật thể chính xác.
- YOLO cũng có Recall khá thấp so với các phương pháp region proposal.
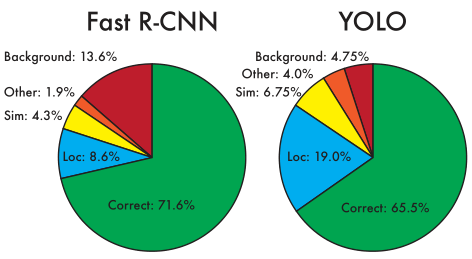
Vì thế, YOLOv2 tập trung chủ yếu vào việc cải thiện recall và localization trong khi vẫn duy trì được classification accuracy, qua đó cải thiện độ chính xác của mô hình. Những sự thay đổi đó bao gồm việc tận dụng lại các công trình làm việc trước đó, đồng thời cũng sáng tạo ra những ý tưởng mới, và được liệt kê dưới đây:
- Batch Normalization: Việc sử dụng batch normalization giúp cải thiện đáng kể convergence mà không cần phải sử dụng regularization. Bằng việc thêm vào batch normalization lên tất cả convolutional layers, performance được cải thiện thêm 2% mAP. Ngoài ra, nó còn giúp regularize mô hình, loại bỏ dropout ra khỏi mô hình mà không xảy ra overfitting.
- Sử dụng Classifier có độ phân giải cao: YOLOv1 huấn luyện Classifier Network ở độ phân giải 224 x 224 và tăng độ phân giải lên 448 x 448 cho việc detect. Điều này có nghĩa là network phải vừa học detect object, vừa điều chỉnh sang độ phân giải mới của ảnh đầu vào.YOLOv2 giải quyết được nhược điểm trên. Đầu tiên, ta fine tune classification network ở độ phân giải 448 x 448 trong 10 epoch trên tập dữ liệu ImageNet. Điều này giúp network có thời gian điều chỉnh filters của nó để hoạt động tốt hơn trên ảnh đầu vào có độ phân giải cao. Sau đó, ta mới fine tune network này cho việc detect. Classification network có độ phân giải cao này làm tăng mAP thêm gần 4%.
- Sử dụng Anchor Box để dự đoán Bounding Box: YOLOv1 dự đoán trực tiếp tọa độ của bounding box bằng các Fully Connected Layers ở ngay sau Convolutional Feature Extractor.YOLOv2 cải tiến điều này bằng việc tận dụng lại ý tưởng về Anchor Box trong Faster R-CNN. Việc làm này giúp network dự đoán các bounding box dễ dàng hơn. Khi đó, YOLOv2 sẽ loại bỏ 2 Fully Connected Layers cuối cùng của YOLOv1, vì việc dự đoán bounding box từ các anchor box và confidence score chỉ cần các Convolutional Layers. YOLOv2 cũng loại bỏ Pooling Layer để output của các Convolutional Layers có độ phân giải cao hơn.Một ưu điểm khác của việc sử dụng anchor box đó là ta sẽ loại bỏ được ràng buộc mỗi ô chỉ được dự đoán một object (class) như trong YOLOv1. Thay vào đó, ta sẽ dự đoán class và objectness cho mọi anchor box. Điều này sẽ làm tăng số lượng object được detect, do mỗi ô sẽ dự đoán được nhiều object hơn.Ngoài ra, YOLOv2 điều chỉnh network để dự đoán trên bức ảnh đầu vào có kích thước $416 \times 416$ thay vì 448 x 448. Lý do là vì ta muốn feature map có số lượng ô lẻ, khi đó sẽ có một grid cell nằm ở trung tâm của feature map. Vì các object, đặc biệt là các object lớn thường có xu hướng nằm ở trung tâm của bức ảnh, nên sẽ tốt hơn khi có một ô nằm ở tâm của bức ảnh để dự đoán các object như thế thay vì 4 grid cell đều nằm liền kề các object đó. Convolutional Layers của YOLO giảm kích thước của bức ảnh với tỉ lệ là 32 nên khi sử dụng ảnh đầu vào có kích thước 416 x 416 sẽ cho output là feature map có kích thước 13 x 13.Tương tự như YOLOv1, việc dự đoán objectness (tồn tại đối tượng hay không) vẫn sẽ dự đoán IOU của ground truth và proposed box, và việc dự đoán class vẫn là dự đoán xác suất có điều kiện của class đó biết rằng tồn tại một object:
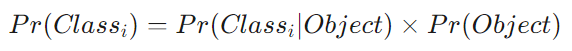 Việc sử dụng anchor box trong YOLOv2 sẽ làm tăng số lượng bounding box được dự đoán lên đến hơn 1000 box trên một bức ảnh (nhiều hơn hẳn so với YOLOv1 với chỉ 98 box mỗi ảnh). Điều này làm giảm accuracy đi một lượng nhỏ. Cụ thể:
Việc sử dụng anchor box trong YOLOv2 sẽ làm tăng số lượng bounding box được dự đoán lên đến hơn 1000 box trên một bức ảnh (nhiều hơn hẳn so với YOLOv1 với chỉ 98 box mỗi ảnh). Điều này làm giảm accuracy đi một lượng nhỏ. Cụ thể:
* YOLOv1 đạt 69.5 mAP, recall = 81%.
* Với anchor box, YOLOv2 đạt 69.2 mAP, recall = 88%.Như vậy, mặc dù mAP của YOLOv2 giảm so với YOLOv1, nhưng recall lại tăng lên một lượng đáng kể. - Ước lượng các Anchor Box: Khi sử dụng anchor box cho YOLOv2, có hai vấn đề nảy sinh. Vấn đề đầu tiên là kích thước ban đầu của anchor box được chọn một cách ngẫu nhiên. Mặc dù network có thể học cách điều chỉnh các box sao cho hợp lý, tuy nhiên, nếu các anchor box được chọn có kích thước đủ tốt thì việc học của network trở nên dễ dàng hơn và vì thế dự đoán được những detection tốt.Người ta nhận thấy rằng trong hầu hết các tập dữ liệu, các bounding box thường có kích thước tuân theo những tỷ lệ và kích cỡ nhất định. Ví dụ như bounding box của người thường sẽ có aspect ratio (tỷ lệ width/height) là 1:3, hay bounding box của ô tô nhìn từ đằng trước thường có aspect ratio là 1:1.Vì vậy, thay vì chọn kích thước ban đầu của anchor box ngẫu nhiên, ta sẽ sử dụng thuật toán K-Means Clustering lên tập các bounding boxes của training set để tự động tìm các kích thước của anchor box, đó sẽ là các anchor box đại diện cho các kích thước bounding box phổ biến trong tập training set.Cơ chế của thuật toán k-means trong việc dự đoán anchor box là như sau:
* Ban đầu, ta sẽ khởi tạo ngẫu nhiên k anchor boxes làm k centroids (tâm cụm) đầu tiên.
* Với mỗi anchor box, ta sẽ tính IOU của từng bounding box với anchor box đó.
* Vì ta muốn các anchor box có IOU tốt so với bounding box, nên ta định nghĩa distance metric như sau: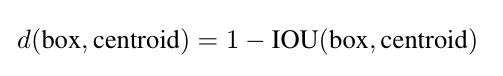 Giải thích công thức trên: Ta có 0 <= IOU <= 1. Bounding box có IOU với anchor box đang xét càng lớn (càng gần 1) thì hai box này có mức độ overlapping càng cao. Suy ra khoảng cách giữa bounding box đó với anchor box đang xét càng nhỏ (càng gần 0), nghĩa là bounding box đang xét có nhiều khả năng thuộc về anchor box đó.
Giải thích công thức trên: Ta có 0 <= IOU <= 1. Bounding box có IOU với anchor box đang xét càng lớn (càng gần 1) thì hai box này có mức độ overlapping càng cao. Suy ra khoảng cách giữa bounding box đó với anchor box đang xét càng nhỏ (càng gần 0), nghĩa là bounding box đang xét có nhiều khả năng thuộc về anchor box đó.
* Sau khi tính xong d(box, centroid) đối với từng anchor box, ta phân các bounding box về các centroids tương ứng rồi cập nhật lại k centroids.
* Lặp lại các bước trên cho đến khi thuật toán hội tụ.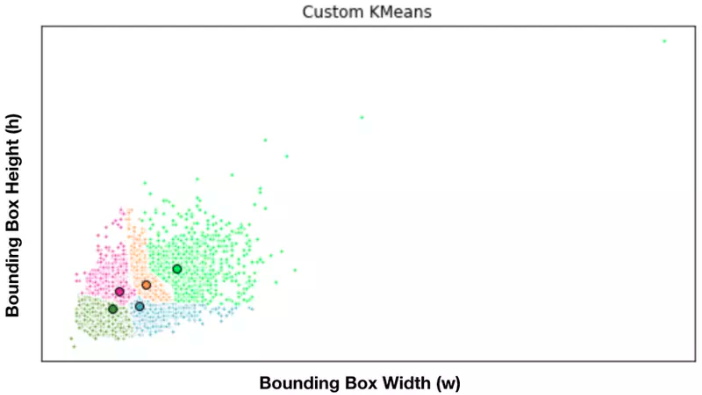 Hình trên là minh họa thuật toán K-Means Clustering trong việc dự đoán các anchor box ở trên, với $k = 5$. Mỗi cụm là một màu khác nhau, tương ứng với màu của tâm (là kích thước của anchor box).
Hình trên là minh họa thuật toán K-Means Clustering trong việc dự đoán các anchor box ở trên, với $k = 5$. Mỗi cụm là một màu khác nhau, tương ứng với màu của tâm (là kích thước của anchor box).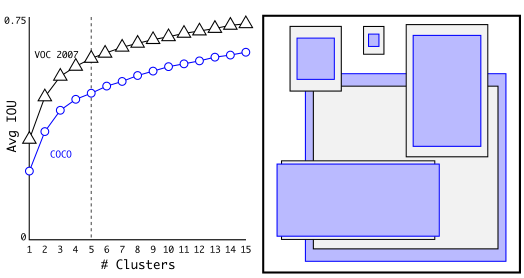 Hình trên là phân cụm anchor box trên các tập dữ liệu VOC và COCO. Hình bên trái biểu diễn giá trị IOU trung bình với các giá trị k khác nhau. Giá tri k = 5 được chọn vì có mức độ tradeoff tốt giữa high recall vs model complexity. Hình bên phải biểu diễn các tâm cụm của hai tập dữ liệu VOC và COCO. Ta thấy COCO có độ biến động kích thước lớn hơn so với VOC. Sau khi thực hiện K-Means, các tâm cụm (là các kích thước anchor box) có khác biệt đáng kể so với anchor boxes được chọn bằng tay.
Hình trên là phân cụm anchor box trên các tập dữ liệu VOC và COCO. Hình bên trái biểu diễn giá trị IOU trung bình với các giá trị k khác nhau. Giá tri k = 5 được chọn vì có mức độ tradeoff tốt giữa high recall vs model complexity. Hình bên phải biểu diễn các tâm cụm của hai tập dữ liệu VOC và COCO. Ta thấy COCO có độ biến động kích thước lớn hơn so với VOC. Sau khi thực hiện K-Means, các tâm cụm (là các kích thước anchor box) có khác biệt đáng kể so với anchor boxes được chọn bằng tay. Bảng trên so sánh average IOU với anchor box gần nhất trên tập dữ liệu VOC 2007, thu được từ thuật toán K-Means Clustering ở trên và chọn anchor boxes bằng tay. Chỉ với k = 5 anchor box, Cluster IOU (hàng thứ 2) đã cho kết quả ngang hàng với Anchor Boxes (hàng thứ 3) với 9 anchor boxes. (61.0 so với 60.9). Khi k = 9 thì Cluster IOU cho giá trị average IOU cao hơn hẳn so với Anchor Boxes với k = 9. Điều này cho thấy việc sử dụng thuật toán K-Means Clustering sẽ giúp cho việc khởi tạo mô hình dễ dàng hơn và các công việc xử lý sau đó được đơn giản hơn.
Bảng trên so sánh average IOU với anchor box gần nhất trên tập dữ liệu VOC 2007, thu được từ thuật toán K-Means Clustering ở trên và chọn anchor boxes bằng tay. Chỉ với k = 5 anchor box, Cluster IOU (hàng thứ 2) đã cho kết quả ngang hàng với Anchor Boxes (hàng thứ 3) với 9 anchor boxes. (61.0 so với 60.9). Khi k = 9 thì Cluster IOU cho giá trị average IOU cao hơn hẳn so với Anchor Boxes với k = 9. Điều này cho thấy việc sử dụng thuật toán K-Means Clustering sẽ giúp cho việc khởi tạo mô hình dễ dàng hơn và các công việc xử lý sau đó được đơn giản hơn. - Dự đoán trực tiếp tọa độ tâm của bounding box: Đây là vấn đề thứ hai ta gặp phải khi sử dụng anchor box, đặc biệt là ở các vòng lặp đầu tiên. Tính bất ổn đó chủ yếu đến từ việc dự đoán tọa độ tâm (x, y) của các bounding box. Nhắc lại rằng trong mạng Region Proposal Network (RPN) của Faster R-CNN, nó sẽ dự đoán hai giá trị t_x, t_y là độ dịch chuyển của bounding box theo hai chiều rộng và chiều cao (w_a, h_a) của anchor box. Khi đó, tọa độ tâm (x, y) của bounding box được tính như sau:
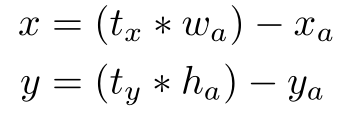
Vấn đề là công thức kia không có sự ràng buộc nào cả. Ví dụ như t_x = 1 sẽ dịch chuyển bounding box sang bên phải một khoảng bằng chiều rộng của bounding box, t_x = -1 sẽ dịch chuyển bounding box sang bên trái một khoảng cách tương tự.
Vì vậy, bounding box được dự đoán sẽ có thể ở bất cứ điểm nào trên bức ảnh, bất kể anchor box dùng để dự đoán bounding box đó nằm ở vị trí nào. Khi đó, mô hình sẽ mất rất nhiều thời gian để có thể ổn định được và dự đoán được những bounding box chính xác.Vì vậy, thay vì dự đoán tọa độ tâm của bounding box từ anchor box, YOLOv2 sẽ sử dụng cách tiếp cận tương tự như YOLOv1, đó là dự đoán trực tiếp tọa độ tâm của bounding box theo vị trí của từng grid cell trong feature map thay vì dự đoán theo vị trí của anchor box. Điều này giúp giới hạn tọa độ của bounding box vào trong đoạn [0, 1]. Để làm được điều đó, ta sẽ sử dụng hàm logistic activation (sigma) để ràng buộc tọa độ của bounding box rơi vào đoạn đó.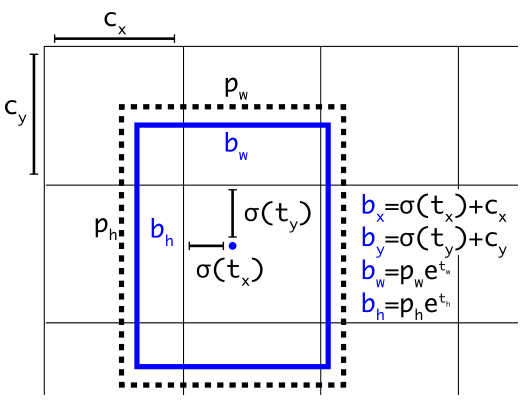 Hình trên là minh họa cho điểu ta vừa nói ở trên. Ta sẽ dự đoán kích thước (chiều rộng và chiều cao) của bounding box (hình chứ nhạt màu xanh da trời) theo kích thước của anchor box (hình chữ nhật nét đứt) thu được từ thuật toán phân cụm ở trên. Còn tọa độ tâm của bounding box sẽ được dự đoán theo vị trí của ô trên feature map sử dụng hàm kích hoạt sigmoid.YOLOv2 dự đoán 5 bounding box mỗi ô trong feature map. Network sẽ dự đoán 5 tọa độ cho mỗi bounding box: t_x, t_y, t_w, t_h, t_o. Nếu ô đó có tọa độ (c_x, c_y) (với tâm tính từ góc bên cùng bên trái của bức ảnh) và anchor box có chiều rộng và chiều cao là p_w, p_h thì dự đoán của bounding box sẽ có công thức sau:
Hình trên là minh họa cho điểu ta vừa nói ở trên. Ta sẽ dự đoán kích thước (chiều rộng và chiều cao) của bounding box (hình chứ nhạt màu xanh da trời) theo kích thước của anchor box (hình chữ nhật nét đứt) thu được từ thuật toán phân cụm ở trên. Còn tọa độ tâm của bounding box sẽ được dự đoán theo vị trí của ô trên feature map sử dụng hàm kích hoạt sigmoid.YOLOv2 dự đoán 5 bounding box mỗi ô trong feature map. Network sẽ dự đoán 5 tọa độ cho mỗi bounding box: t_x, t_y, t_w, t_h, t_o. Nếu ô đó có tọa độ (c_x, c_y) (với tâm tính từ góc bên cùng bên trái của bức ảnh) và anchor box có chiều rộng và chiều cao là p_w, p_h thì dự đoán của bounding box sẽ có công thức sau: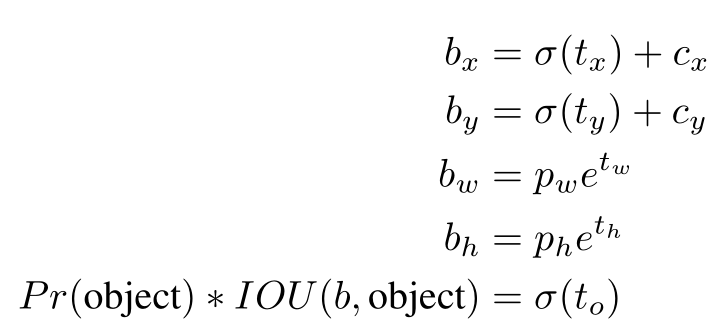 Công thức cuối cùng là là dự đoán confidence score của bounding box b.Vì ta giới hạn vị trí của bounding box dự đoán nên việc học sẽ trở nên đơn giản hơn, qua đó giúp network ổn định hơn. Việc sử dụng phân cụm anchor box cùng với việc dự đoán trực tiếp tọa độ của bounding box theo từng ô của feature map làm mAP tăng thêm gần 5% so với phiên bản YOLO dự đoán vị trí của bounding box theo vị trí của anchor box.
Công thức cuối cùng là là dự đoán confidence score của bounding box b.Vì ta giới hạn vị trí của bounding box dự đoán nên việc học sẽ trở nên đơn giản hơn, qua đó giúp network ổn định hơn. Việc sử dụng phân cụm anchor box cùng với việc dự đoán trực tiếp tọa độ của bounding box theo từng ô của feature map làm mAP tăng thêm gần 5% so với phiên bản YOLO dự đoán vị trí của bounding box theo vị trí của anchor box. - Sử dụng các đặc trưng chi tiết hơn: YOLOv2 dự đoán detection trên feature map kích thước 13 x 13 – đủ để dự đoán các vật thể có kích thước lớn. Hơn nữa, nó còn khắc phục được nhược điểm của YOLOv1 – khó khăn trong việc dự đoán các vật thể nhỏ – bằng việc sử dụng nhiều feature map có kích thước khác nhau (lấy ý tưởng từ Faster R-CNN và SSD). Điều này sẽ giúp cải thiện việc dự đoán các đối tượng có kích thước nhỏ từ các features “mịn” hơn (finer grained features). Cụ thể là YOLOv2 sẽ thêm một feature map có kích thước 26 x 26 bằng việc thêm vào một Passthrough Layer giúp lấy được feature từ layer trước đó với độ phân giải cao hơn (26 x 26). Passthrough layer có tác dụng nối (concatenate) feature map 13 x 13 với feature map 26 x 26 để tạo thành một khối thống nhất cho việc dự đoán. Tuy nhiên, làm sao thế nào để có thể nối hai khối feature map có kích thước khác nhau?Thông thường, việc nối 2 feature map chỉ có thể thực hiện được khi chúng có cùng width và height. Trong bái báo, tác giả chỉ đơn giản nói là (nguyên văn): “The passthrough layer concatenates the higher resolution features with the low resolution features by stacking adjacent features into different channels instead of spatial locations, similar to the identity mappings in ResNet. This turns the 26 x 26 x 512 feature map into a 13 x 13 x 2048 feature map, which can be concatenated with the original features”.Qua tìm hiểu, kĩ thuật chuyển đổi kích thước feature map ở trên được gọi là Reorg. Đây bản chất chỉ là kĩ thuật tổ chức lại (reorganize) bộ nhớ để biến feature map n x n x c_1 thành k x k x c_2, k <= n, bằng việc tăng chiều sâu của feature map, tức c_1 <= c_2. Ta sẽ không đi quá chi tiết ở đây, mà chỉ nói những ý chính của kỹ thuật này. Để có thể hiểu hơn về Reorg, mời bạn đọc 2 bài sau (có cả code):
Bài Tiếng Anh
Bài Tiếng Việt
Ý tưởng chính của kĩ thuật này là như sau. Giả sử ta muốn giảm kích thước dài, rộng đi mỗi cạnh 2 lần thì số channel phải được tăng lên 4 lần. Việc biến đổi này hoàn toàn không giống phép resize trong xử lý ảnh. Để dễ hình dung, bạn có thể xem hình vẽ dưới đây: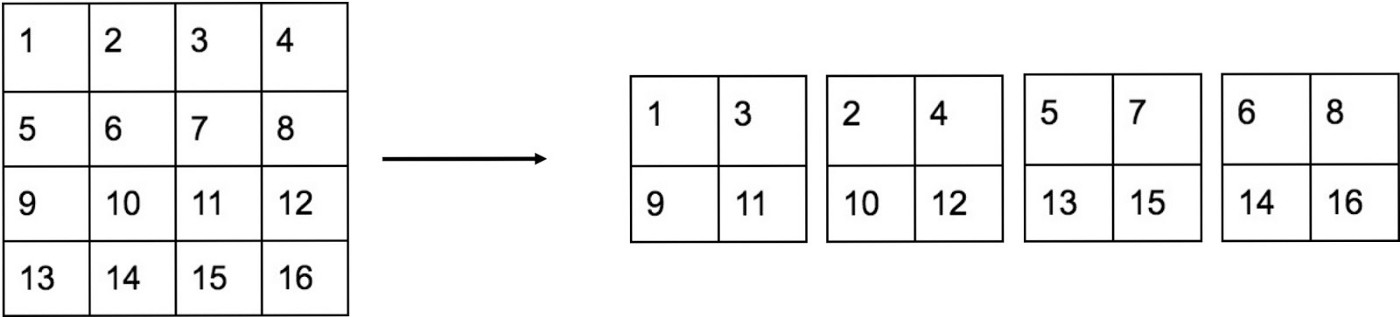 Hình trên là một feature map kích thước 4 x 4. Để đưa feature map về kích thước 2 x 2, tức là giảm chiều rộng đi 2 lần và chiều dài đi 2 lần, ta tách feature map 4 x 4 thành 4 ma trận như hình bên trái ở trên, ứng với 4 channel của feature map 2 x 2 mới, với cơ chế sắp xếp lại vị trí các phần tử như sau: vị trí của các giá trị trong mỗi channel của feature map 2 x 2 mới sẽ lấy cách đều trên feature map 4 x 4 ban đầu với stride = 2 theo cả chiều dài và chiều rộng.Như vậy, việc sử dụng kỹ thuật Reorg đã biến features map 26 x 26 x 512 thành feature map x13 x 13 x 2048 (giảm width và height đi một nửa, tăng channel lên gấp 4), và do vậy có thể nối feature map này với feature map ban đầu. Detector sẽ chạy trên feature map mở rộng này, nó có thể truy cập được vào các đặc trưng “mịn” hơn, giúp detect tốt các object nhỏ. Điều này làm tăng performance thêm 1%.
Hình trên là một feature map kích thước 4 x 4. Để đưa feature map về kích thước 2 x 2, tức là giảm chiều rộng đi 2 lần và chiều dài đi 2 lần, ta tách feature map 4 x 4 thành 4 ma trận như hình bên trái ở trên, ứng với 4 channel của feature map 2 x 2 mới, với cơ chế sắp xếp lại vị trí các phần tử như sau: vị trí của các giá trị trong mỗi channel của feature map 2 x 2 mới sẽ lấy cách đều trên feature map 4 x 4 ban đầu với stride = 2 theo cả chiều dài và chiều rộng.Như vậy, việc sử dụng kỹ thuật Reorg đã biến features map 26 x 26 x 512 thành feature map x13 x 13 x 2048 (giảm width và height đi một nửa, tăng channel lên gấp 4), và do vậy có thể nối feature map này với feature map ban đầu. Detector sẽ chạy trên feature map mở rộng này, nó có thể truy cập được vào các đặc trưng “mịn” hơn, giúp detect tốt các object nhỏ. Điều này làm tăng performance thêm 1%.
- Huấn luyện trên các bức ảnh có kích thước khác nhau: Vì YOLOv2 chỉ sử dụng Convolutional Layers và Pooling Layer nên nó có thể resize ảnh đầu vào trong quá trình chạy thuật toán. Do đó, YOLOv2 có thể thích nghi tốt với nhiều bức ảnh đầu vào có kích thước khác nhau. Tác giả đã huấn luyện mạng trên nhiều kích thước ảnh khác nhau để tăng khả năng thích ứng của YOLOv2 với đa dạng kích thước ảnh. Điều này có nghĩa là YOLOv2 có thể đưa ra dự đoán tại các độ phân giải khác nhau.
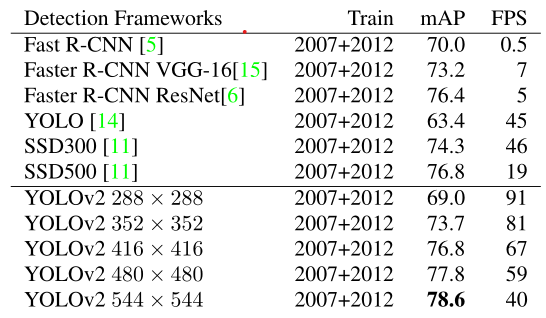
Bảng trên so sánh các hệ thống detection trên tập dữ liệu test PASCAL VOC 2007. Ta có thể thấy YOLOv2 vừa nhanh hơn và chính xác hơn các hệ thống detection đời trước. YOLOv2 sẽ chạy nhanh hơn với các bức ảnh có kích thước nhỏ. Ở độ phân giải cao nhất, YOLOv2 đạt được độ chính xác lớn nhất với 78.6 mAP trong khi vẫn đạt được tốc độ lớn hơn thời gian thực (40 FPS). Hơn nữa, nó có thể chạy tại các độ phân giải khác nhau mà không đánh đổi quá nhiều giữa speed và accuracy.
2.2. Nhanh hơn
YOLOv2 cho kết quả dự đoán chính xác hơn, đồng thời tốc độ của nó cũng nhanh hơn. Để làm được điều đó, kiến trúc mạng của nó đã có sự thay đổi đáng kể so với YOLOv1.
Thay vì sử dụng custom network dựa trên kiến trúc GoogLeNet, YOLOv2 sử dụng một classification model mới để làm base network, có tên là Darknet-19. Nó bao gồm 19 Convolutional Layers và 5 Maxpooling Layers. Hình dưới đây mô tả kiến trúc cụ thể của Darknet-19.
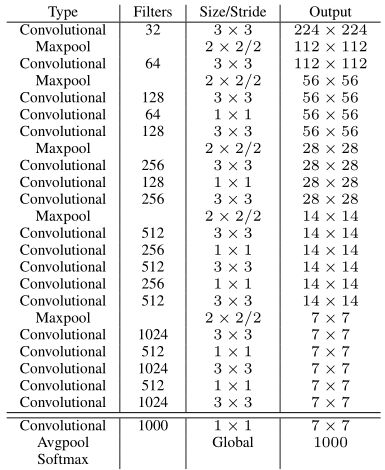
Darknet-19 chỉ cần 5.58 tỉ phép toán để xử lý một bức ảnh, trong khi với kiến trúc của YOLOv1 là 8.52 tỉ phép toán, trong khi vẫn đạt được 72.9% top-1 accuracy và 91.2% top-5 accuracy trên tập dữ liệu ImageNet. Như vậy, có thể thấy được là tốc độ của YOLOv2 được tăng lên đáng kể (34%) so với YOLOv1.
Ta tổng kết lại những ý trên bẳng bảng dưới đây:
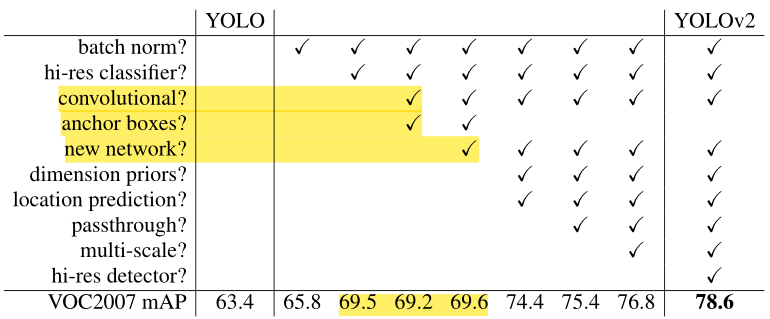
Hầu hết các ý tưởng được liệt kê ở bảng trên đều làm tăng mAP thêm đáng kể, ngoại trừ việc chuyển sang dùng mạng Fully Convolutional Network với Anchor Box và sử dụng một mạng backbone mới. Việc chuyển sang dùng Anchor Box làm tăng recall lên trong khi gần như vẫn giữa nguyên mAP (từ 69.5 xuống 69.2), còn việc sử dụng một mạng backbone mới làm giảm chi phí tính toán đi 34%. (mAP từ 69.2 lên 69.6).
2.3. Mạnh hơn
Mặc dù các hệ thống detection ngày càng nhanh và chính xác, tuy nhiên chúng vẫn bị ràng buộc bởi một tập hợp nhỏ các đối tượng. Các tập dữ liệu cho object detection bị giới hạn rất nhiều so với các tác vụ khác như classification và tagging. Tập dữ liệu detection phổ biến nhất chứa từ hàng nghìn đến hàng trăm nhìn bức ảnh, với số lượng nhãn chỉ từ từ hàng chục đến hàng trăm. Còn các tập dữ liệu classification rất hơn rất nhiều, bao gồm hàng triệu bức ảnh với hàng chục hoặc hàng trăm nghìn class.
Việc làm tăng kích thước và số lượng các class cho tập dữ liệu detection không hề đơn giản chút nào vì gán nhãn ảnh cho việc detect tốn kém hơn rất nhiều so với gán nhãn cho việc classification hay tagging (vì ngoài việc gán nhãn cho các class, ta còn phải gán các tọa độ bounding box sao cho chính xác, việc này cực kỳ tốn nhiều thời gian). Vì thế, ta sẽ khó có thể thấy tập dữ liệu detection sẽ có quy mô và độ lớn như tập dữ liệu classification trong tương lai gần.
Vì thế, tác tác giả đề xuất hai giải pháp sau:
- Đề xuất một phương pháp khai thác số lượng lớn dữ liệu classification đang có, dùng nó để mở rộng phạm vi đối tượng nhận diện cho hệ thống detection. Phương pháp này giúp ta có thể kết hợp các tập dữ liệu khác nhau lại cùng nhau.
- Đề xuất một thuật toán huấn luyện đồng thời giúp ta có thể huấn luyện object detectors trên cả hai tập dữ liệu classification và detection. Phương pháp này sử dụng:
- Các bức ảnh detection đã được gán nhãn để học các thông tin về việc detect: dự đoán tọa độ bounding box để dự đoán chính xác đối tượng, objectness (tồn tại đối tượng hay không), cách để phân loại các đối tượng phổ biến.
Các bức ảnh classification để tăng vốn từ vựng – mở rộng số lượng class có thể dự đoán – qua đó làm cho YOLOv2 trở nên mạnh mẽ hơn.
Để thực hiện được hai điều trên, trong quá trình huấn luyện, thuật toán sẽ trộn lẫn các bức ảnh từ hai tập dữ liệu classification và detection lại với nhau:
- Khi network nhìn thấy một bức ảnh được gán nhãn cho detection, nó sẽ backpropagate sai số trên toàn bộ hàm loss function.
Khi network nhìn thấy một bức ảnh được gán nhãn cho classification, nó chỉ backpropagate sai số từ các thành phần classification error của hàm loss.
Lúc này, có một vấn đề mới xuất hiện, đó là các tập dữ liệu detection chỉ có các đối tượng phổ biến và các nhãn tổng quát, ví dụ như “chó”, “người”, “thuyền”. Ví dụ như tập dữ liệu COCO bên dưới với 80 class mang ý nghĩa chung:
Trong khi đó, tập dữ liệu classification có số lượng nhãn vừa nhiều hơn vừa có chiều sâu hơn. Ví dụ như tập dữ liệu ImageNet (hình bên dưới) (22k class) có hơn một trăm giống chó, như “Norfolk terrier”, “Yorkshire terrier”, “Bedlington terrier”,… Vì vậy, ta cần tìm cách hợp nhất các nhãn có quan hệ với nhau để có thể huấn luyện đồng thời trên các tập dữ liệu.
Hầu hết các phương pháp phân loại sử dụng hàm Softmax Layer để phân loại vật thể, nó sẽ giả định mỗi ảnh chỉ có một label. Tuy nhiên, ta không thể áp dụng được hàm đó lên tập dữ liệu ImageNet vì một ảnh có thể có nhiều hơn một label, ví dụ như “Norfolk terrier” và “dog”. Ta có thể sử dụng các mô hình multi-label để giải quyết vấn đề này, tuy nhiên nó lại gặp bất lợi trong tập dữ liệu detection COCO, vì các ảnh trong tập dữ liệu này chỉ có một label. Như vậy, ta có thể thấy được có một sự mâu thuẫn giữa các tập dữ liệu detection và classification.
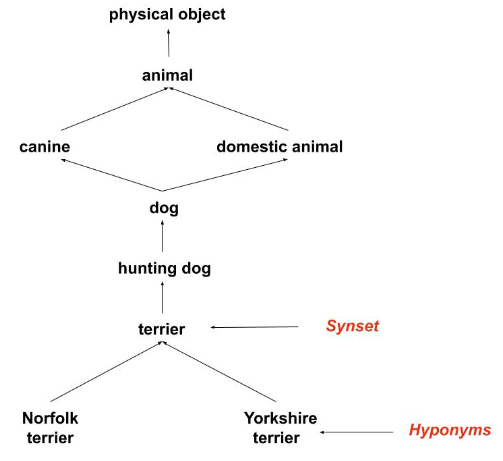
Các nhãn của tập dữ liệu ImageNet được lấy từ WordNet – một cơ sở dữ liệu ngôn ngữ dùng để cấu trúc hóa các khái niệm và mối quan hệ của chúng với nhau. Trong WordNet, “Norfolk terrier” và “Yorkshire terrier” đều là hạ vị (hyponym – một từ có ý nghĩa cụ thể hơn và nằm bên trong nghĩa của một từ khác) của “terrier” – là một thể loại trong “hungting dog” – là một thể loại của “dog”.
Hầu hết các phương pháp phân loại giả sử một cấu trúc phẳng – các từ có nghĩa ngang hàng, độc lập và tách biệt với nhau, không có độ sâu của từ (không có từ nào nằm trong nghĩa của một từ khác). Tuy nhiên, để có thể kết hợp các tập dữ liệu lại thì ta cần phải xây dựng cấu trúc cho các class.
WordNet có cấu trúc là một đồ thị có hướng, không phải là một cây, vì ngôn ngữ rất phức tạp. Ví dụ, “chó” đều thuộc “họ chó” và “động vật nuôi”, tức “dog” thuộc vào hai nhánh khác nhau.
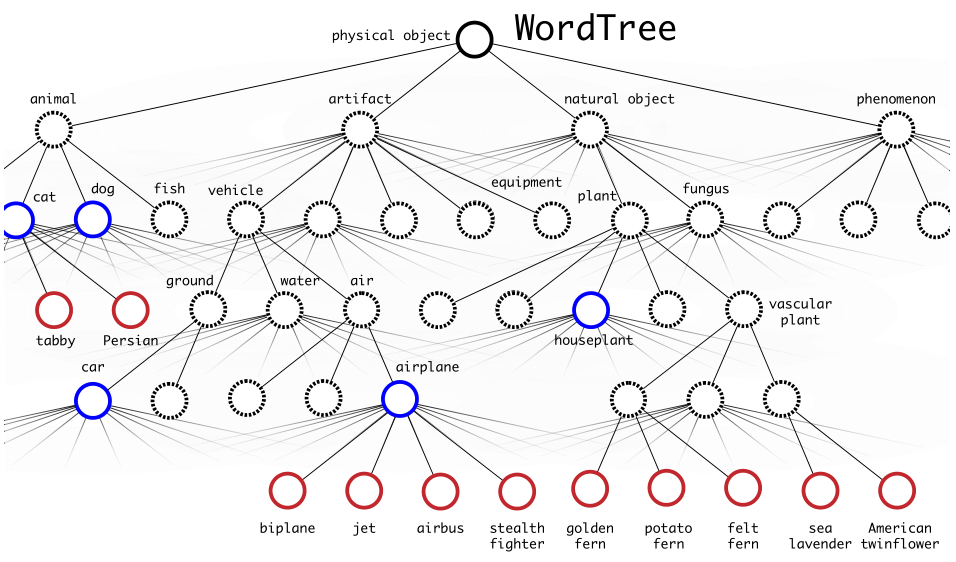
Ta sẽ dựa vào cấu trúc của WordNet để xây dựng một cây thứ bậc – hierarchical tree từ các khái niệm trong tập dữ liệu ImageNet, chỉ sử dụng visual nouns (các danh từ hữu hình), với root node là “physical object”. Cách thức thực hiện là như sau:
- Trước tiên, ta sẽ thêm vào những nhánh mà chỉ có một đường đi duy nhất từ root node.
- Với những concepts bị bỏ lại, ta thêm path làm cây phát triển ít nhất có thể. Ví dụ: nếu một concepts có hai đường đi từ root, một path sẽ thêm ba cạnh vào cậy, path còn lại chỉ thêm một cạnh vào cây, thì ta sẽ chọn path ngắn hơn.
Ta gọi kết quả thực hiện ở trên là WordTree – một mô hình cấp bậc cho các khái niệm hữu
hình (visual concepts):
Để thực hiện việc phân loại trên WordTree, ta dự xác suất của một đối tượng dựa vào tích của các xác suất có điều kiện, đi từ node đó đến root node (ta giả sử bức ảnh chứa vật thể nên Pr(physical object) = 1). Ví dụ:

3. Kết luận
Như vậy là ta đã giới thiệu và trình bày chi tiết về YOLOv2 và YOLO9000 và những cải tiến của chúng so với phiên bản YOLO đầu tiên. YOLOv2 cho kết quả tốt hơn và tốc độ nhanh hơn các hệ thống nhận diện khác trên các bộ dữ liệu detection khác nhau. Hơn nữa, nó có thể xử lý các bức ảnh với những kích thước khác nhau mà không phải đánh đổi nhiều giữa speed và accuracy.
YOLOv2 được cải tiến thêm bằng việc huấn luyện đồng thời giữa tập dữ liệu detection và classification, từ đó cho ra phiên bản YOLO9000 với khả năng dự báo hơn 9000 vật thể. Ta sử dụng WordTree để kết hợp kết hợp dữ liệu từ nhiều nguồn khác nhau và kỹ thuật tối ưu để huấn luyện đồng thời trên tập dữ liệu ImageNet và COCO. YOLO9000 đánh dấu một bước tiến lớn trong việc thu hẹp khoảng cách giữa tập dữ liệu detection với classification.
4. Tài liệu tham khảo
- YOLO9000: Better, Faster, Stronger
- Understanding YOLO and YOLOv2
- YOLO_v2 and YOLO9000 Part 1
- YOLO_v2 and YOLO9000 Part 2
Like và follow fanpage của Pixta Việt Nam để cập nhật các thông tin công nghệ hữu ích nhé!
Tác giả/Writer: Nguyễn Duy Hảo
