
YOLOv1 – nhận diện vật thể chỉ ngó một lần
Mục lục
- Giới thiệu
- Chi tiết
- Giới hạn của YOLO
- Kết quả
- Kết luận
- Tài liệu tham khảo
Xem thêm bài viết về YOLOv2 tại đây.
1. Giới thiệu
Ở thời điểm YOLO được ra mắt bởi Facebook AI Research (FAIR), các công trình trước đó về Object Detection đều sử dụng các bộ phân loại (classifiers) và điều chỉnh lại nó để phù hợp hơn trong việc thực hiện nhận diện đối tượng. YOLO sử dụng một cách tiếp cận hoàn toàn mới, coi nhận diện đối tượng là một bài toán hồi quy (regression problem) cho các bounding boxes và class probabilities tương ứng.
YOLO chỉ sử dụng một mạng neural network duy nhất để dự đoán trực tiếp bounding boxes và class probabilities từ toàn bộ bức ảnh bằng một lần đánh giá duy nhất (one evaluation). Vì vậy, ta chỉ cần nhìn một lần duy nhất vào bức ảnh để có thể dự đoán vật thể trong ảnh và vị trí của chúng. Đó cũng chính sự giải thích cho cái tiên YOLO – You Only Look Once (bạn chỉ cần nhìn một lần duy nhất). Cũng chính vì lý do đó mà tốc độ xử lý của YOLO là cực kì nhanh. Toàn bộ quá trình detection là một mạng duy nhất nên nó có thể được tối ưu toàn bộ từ đầu đến cuối.

Các hệ thống detection ở thời điểm đó thường sử dụng một bộ phân loại để đánh giá (evaluate) đối tượng ở nhiều vị trí và độ phóng đại (scale) khác nhau trong một bức ảnh test. Một số hệ thống nổi bật ở thời điểm đó là Deformable Parts Models (DPM) với phương pháp sử dụng cửa sổ trượt (sliding window), ở đó classifiers sẽ được chạy ở các vị trí cách đều nhau trên toàn bộ bức ảnh, hay các mô hình nổi tiếng họ nhà R-CNN sử dụng phương pháp đề xuất vùng (region proposal method) để trước tiên tạo ra các bounding box có khả năng chứa đối tượng trong một bức ảnh, rồi sau đó chạy một classifier lên các proposed box đó để phân loại đối tượng. Sau khi phân loại, post-processing được sử dụng để tinh chỉnh lại bounding boxes, loại bỏ duplicate detections,… Cơ chế pipeline phức tạp này thường rất chậm và rất khó để tối ưu vì mỗi thành phần riêng lẻ cần phải được train tách biệt nhau.
YOLO, trái ngược với các phương pháp ở trên, lại cực kì đơn giản. Nó sử dụng một mạng CNN duy nhất để đồng thời dự đoán bounding boxes và class probabilities cho các boxes đó. Hơn nữa, YOLO được train trên toàn bộ bức ảnh – trái ngược với các phương pháp ở trên chỉ train trên từng vùng nhỏ của bức ảnh – vì thế trực tiếp tối ưu hóa hiệu quả tìm kiếm.

Hình trên là một ví dụ minh hoạ về hệ thống detection của YOLO. Việc xử lý ảnh với YOLO rất đơn giản và dễ dàng. Mô hình trên bao gồm 3 bước:
1. Resize ảnh đầu vào về kích thước 448 x 448.
2. Chạy một mạng CNN lên bức ảnh.
3. Tinh chỉnh kết quả của mô hình.
Mô hình thống nhất của YOLO có một vài ưu điểm so với các phương pháp object detection truyền thống như sau:
1. Thứ nhất, YOLO có tốc độ xử lý cực kì nhanh. Vì YOLO coi object detection là một bài toán hồi quy nên ta không cần dùng đến một cơ chế pipeline phức tạp. Ta chỉ đơn giản chạy neural network trên một bức ảnh mới tại test time để dự đoán detections. Base network của YOLO có tốc độ là 45 FPS, và fast version của YOLOv1 (có tên là Fast YOLO) có tốc độ hơn 150 FPS. Điều này giúp ta có thể xử lý streaming video trong thời gian thực (real-time) với độ trễ (latency) nhỏ hơn 25 milliseconds. YOLO đạt được độ chính xác mAP hơn gấp đôi so với các hệ thống real-time khác.
2. Thứ hai, YOLO lập luận một cách toàn cục về bức ảnh khi đưa ra dự đoán. Không giống như các phương pháp cửa sổ trượt hay đề xuất vùng được nhắc đến ở trên, YOLO nhìn vào toàn bộ bức ảnh trong thời gian training và test, vì thế nên nó ngầm hiểu thông tin về ngữ cảnh (contextual information) về các classes cũng như là ngoại hình (appearance) của chúng. Vì thế background errors của YOLO nhỏ hơn đáng kể so với các phương pháp khác, ví dụ như Fast R-CNN.
3. Thứ ba, cũng là điểm mới mẻ nhất: YOLO có khả năng học được các biểu diễn có tính tổng quát hóa (generalizable representations) của vật thể. Khi train YOLO với những bức ảnh thực và test bằng những tấm ảnh vẽ (art-work), YOLO có kết quả vượt trội so với các phương pháp detection hàng đầu khác như DPM hay R-CNN. Vì YOLO có tính tổng quát hóa rất cao nên nó ít khi thất bại khi được đưa vào các lĩnh vực mới hay sử dụng các input bất thường.

Hình trên là kết quả dự đoán của YOLO trên các bức ảnh vẽ (art-work) và các bức ảnh thực từ internet. Nó cho kết quả dự đoán hầu hết đều chính xác, mặc dù nó nghĩ một người là một cái máy bay. (Hình thứ 7 từ trái qua phải, từ trên xuống dưới.)
Tuy vậy, YOLO vẫn đứng sau các hệ thống detection hàng đầu khác về độ chính xác. Trong khi nó có thể xác định một cách nhanh chóng các vật thể trong bức ảnh, nó lại gặp khó khăn trong việc định vị chính xác một vài vật thể, đặc biệt là các vật thể nhỏ.
2. Chi tiết
2.1. Cách thức hoạt động
YOLO chia một bức ảnh đầu vào thành một ô lưới có kích thước S x S. Giá trị S được chọn bằng 7 trong paper. Nếu tâm của một vật thể rơi vào một ô nào thì ô đó sẽ chịu trách nhiệm cho việc tìm kiếm vật thể đó.

Hình trên là một ví dụ về một bức ảnh đầu vào được chia thành một ô lưới có kích thước S x S. Trong YOLO, giá trị S được chọn bằng 7.
Mỗi grid cell sẽ dự đoán B bounding boxes và confidence score cho mỗi box đó. Ta sẽ xét kỹ hơn hai khái niệm này ngay dưới đây.
Confidence score sẽ phản ánh hai thông số:
- Mức độ tự tin của mô hình trong việc dự đoán box đó chứa vật thể.
- Độ chính xác của predicted box là bao nhiêu (tức box đó khớp với ground-truth box đến mức nào).
Từ hai ý trên, ta định nghĩa confidence score một cách chặt chẽ hơn như sau:
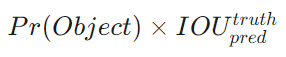
Từ công thức trên, ta có thể rút ra một vài nhận xét như sau:
- Nếu không có vật thể nào tồn tại trong cell đó thì Pr(Object) = 0, suy ra confidence score bằng 0.
- Ngược lại, nếu cell đó chứa vật thể thì suy ra Pr(Object) = 1, vì thế ta kỳ vọng confidence score bằng giá trị IOU giữa predicted box và ground truth box.
Mỗi bounding box sẽ bao gồm 5 dự đoán: x, y, w, h, confidence.
- (x, y) là tọa độ tâm (offset) của bounding box so với với vị trí của của grid cell, vì thế nên giá trị của x, y sẽ rơi vào đoạn [0, 1].
- w, h là width, height của bounding boxes, được chuẩn hóa theo width và height của bức ảnh gốc, vì thế giá trị của chúng sẽ rơi vào đoạn [0, 1].
- Confidence biểu diễn giá trị IOU giữa predicted box và ground truth box.
Mỗi grid cell cũng sẽ dự đoán C xác suất có điều kiện của các class:
![]()
Các xác suất này được lấy điều kiện trên grid cell chứa đối tượng.
- NOTE: YOLO chỉ dự đoán một tập class probabilities trên mỗi grid cell, bất kể số lượng bounding boxes B là bao nhiêu.
Tại thời điểm test, ta nhân xác suất có điều kiện của mỗi class với dự đoán confidence của từng box như sau:
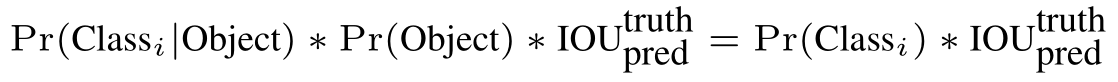
Công thức trên cho ta confidence scores của từng class cho mỗi box. Công thức này cho ta biết:
- Xác suất của class thứ i xuất hiện trong box đó
- Độ khớp của của predicted box so với vật thể.
Ta tóm gọn lại quy trình hoạt động của YOLOv1 như hình dưới đây:
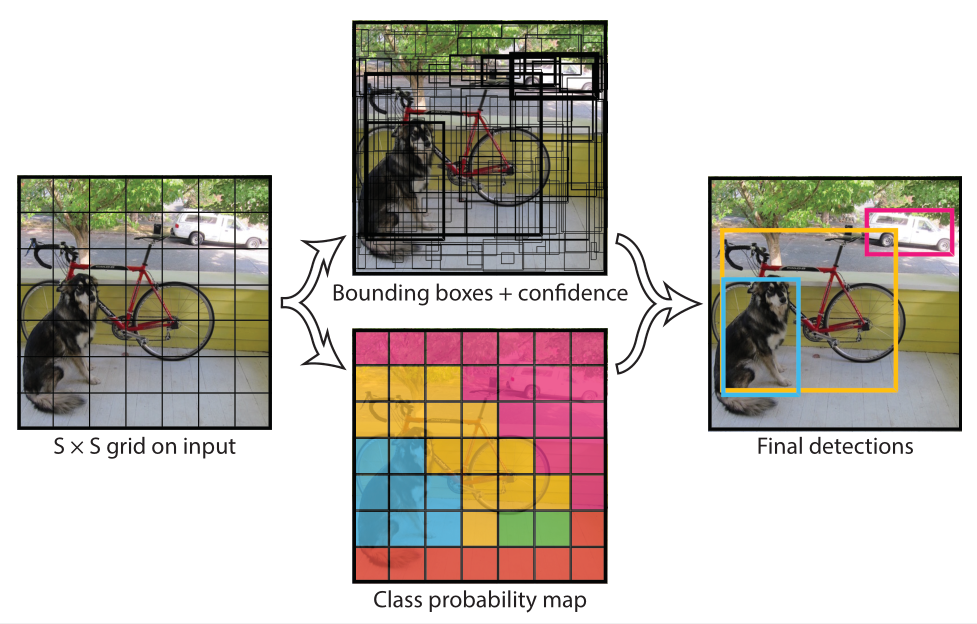
Như vậy, tổng kết lại, mỗi grid cell sẽ dự đoán B bounding boxes và confidence score cho mỗi box đó, cộng thêm C class probabilities. Dự đoán được encode thành một tensor có kích thước S x S x (B x 5 + C). Khi thực hiện YOLO trên tập dữ liệu PASCAL VOC, S = 7, B = 2. PASCAL VOC có 20 class được gán nhãn, nên C = 20. Suy ra dự đoán cuối cùng là một tensor có kích thước 7 x 7 x (2 x 5 + 20) = 7 x 7 x 30.
2.2. Network Design
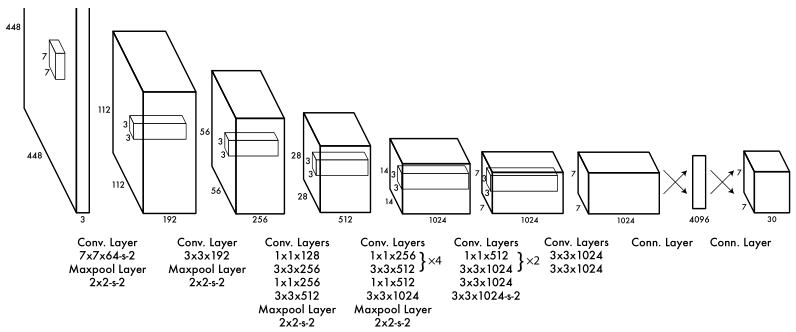
Kiến trúc mạng YOLOv1 được lấy ý tưởng từ mô hình GoogLeNet cho phân loại ảnh. Nó gồm có 24 Convolutional Layers dùng để trích xuất các features từ bức ảnh, theo sau bởi 2 Fully Connected Layers để dự đoán output probabilities và coordinates. Thay vì sử dụng inception modules trong GoogLeNet, YOLO chỉ sử dụng reduction layers có kích thước 1 x 1 theo sau bởi Convolutional Layers có kích thước 3 x 3. Layer cuối cùng của network là các dự đoán ở dạng tensor với kích thước 7 x 7 x 30.
Các Convolutional Layers được pretrain trên trên tập dữ liệu ImageNet cho việc phân loại ảnh với độ phân giải 224 x 224, rồi sau đó gấp đôi độ phân giải cho việc detection.
2.3. Training
YOLOv1 sử dụng hàm loss là SSE (Sum of Square Error – Tổng bình phương sai số). Hàm này có ưu điểm là dễ tối ưu, tuy nhiên nó lại có một số nhược điểm sau:
- SSE đánh giá localization error bằng với classification error. Điều này không tốt vì error scale của hai loại này là khác nhau.
- Trong một bức ảnh, có nhiều grid cell không chứa object. Điều này đẩy confidence score của các grid cell đó về gần 0, và một số lượng lớn grid cell không chứa object sẽ áp đảo gradient từ những grid cell có chứa object (giống Focal Loss). Điều này gây ra sự bất ổn định cho mô hình, khiến quá trình huấn luyện diverge sớm.
- SSE đánh giá sai số của box lớn bằng với box nhỏ. Rõ ràng độ lệch nhỏ trong box lớn sẽ ít ảnh hưởng hơn so với độ lệch nhỏ trong box nhỏ.
Vì thế, YOLO đề xuất giải pháp lần lượt như sau:
- Tăng loss từ cho việc dự đoán bounding box coordinates (giữ nguyên classification error) bằng việc sử dụng tham số lambda_coord = 5 (coord là viết tắt của coordinate) để làm tăng sai số từ những dự đoán tọa độ bounding box.
- Giảm loss cho việc dự đoán confidence của những bounding box không chứa vật thể bằng việc sử dụng tham số lambda_noobj = 5 (noobj là viết tắt của no object) để làm giảm sai số từ những grid cell không chứa object.
- Thay vì dự đoán width và height trực tiếp của bounding box, ta dự đoán căn bậc hai của width và height của bounding box.
Còn một điều cần lưu ý nữa. YOLO dự đoán nhiều bounding box mỗi grid cell. Tại thời điểm train, sẽ chỉ có một bounding box chịu trách nhiệm cho việc dự đoán object trong cell đó. Bounding box được chọn sẽ có giá trị IOU cao nhất với ground truth box. Điều này sẽ dẫn đếnn sự chuyên môn hóa giữa các bounding box predictors. Mỗi predictors sẽ trở nên tốt hơn trong việc dự đoán kích thước, aspect ratios (tỉ lệ width/height), class of object nào đó, từ đó cải thiện recall.
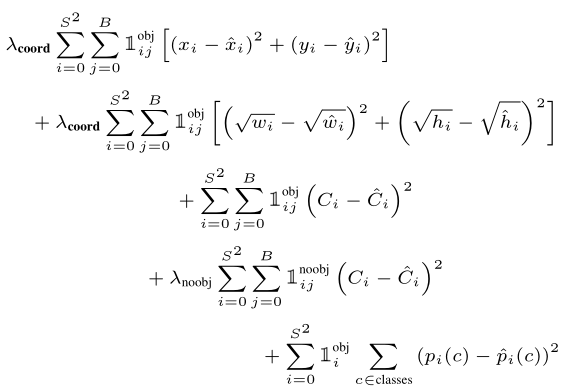
Hình trên là công thức sai số của YOLO. Ta sẽ lần lượt giải thích từng số hạng ở trên. Trước tiên, để ý hai làm \$\mathcal{1}_{ij}^{obj}$ và $\mathcal{1}_{i}^{obj}\$. Đây đều là hàm indicator, chúng nhận hai giá trị như sau:
- \mathcal{1}_{i}^{obj} bằng 1 nếu tồn tại object trong ô thứ i, bằng 0 nếu ngược lại.
- \mathcal{1}_{ij}^{obj} bằng 1 nếu bounding box thứ j của grid cell i chịu trách nhiệm cho việc dự đoán object, bằng 0 nếu ngược lại.
Khi đó, ta giải thích từng số hạng trong hàm loss như sau:
- Localization Error: sai số của tọa độ tâm (offset) (x, y) của bounding box tương ứng với vị trí của một grid cell cụ thể. SSE chỉ ước lượng giá trị này khi cell i tồn tại object và bounding box thứ j chịu trách nhiệm cho việc dự đoán object trong cell i.
- Localization Error: sai số của width và height. Chú ý rằng ở đây ta lấy căn bậc hai của width và height, nó sẽ giải quyết được phần nào vấn đề độ lệch của các box nhỏ và box lớn (độ lệch nhỏ trong box nhỏ sẽ quan trọng hơn trong box lớn).
- Confidence Error: Sai số khi dự đoán bounding box thứ j trong grid cell thứ i có chứa object.
- Confidence Eror: Sai số khi dự đoán bounding box thứ j trong grid cell thứ i không chứa object.
- Confidence Eror: Sai số của xác suất các class trong grid cell thứ i nếu grid cell đó chứa object.
Ta tổng kết lại các ý trên bằng hình dưới đây:

2.4. Inference
Giống như khi training, việc dự đoán detections cho một bức ảnh test chỉ cần một lần đánh giá (network evaluation) duy nhất. Điều này làm cho tốc độ của YOLO ở thời điểm test cực kỳ nhanh so với các phương pháp classifier-based khác.
Trên tập dữ liệu PASCAL VOC, YOLO dự đoán 98 bounding boxes mỗi bức ảnh và class probabilities cho mỗi box. Điều này là dễ hiểu vì 7 x 7 x 2 = 98$.
Các dự đoán bounding box thường có kích thước đa dạng. Thông thường, việc một object rơi vào một grid cell nào đó khá là rõ ràng và network chỉ dự đoán một bounding box cho mỗi object. Tuy nhiên, có thể có trường hợp có một số object có kích thước lớn nên nó có thể rơi vào nhiều cell, hoặc các objects có thể rơi vào phần biên của nhiều cell khác nhau và vì thế, chúng có thể được định vị (localize) bởi nhiều cells khác nhau. Khi đó, có một vấn đề nảy sinh, đó chính là sự trùng lặp dự đoán – việc nhiều cells khác nhau cùng dự đoán một object. Khi đó, kỹ thuật Non-Max Suppression (NMS) có thể được dùng để giải quyết vấn đề này. Việc sử dụng kĩ thuật này làm tăng mAP lên 2-3%.

3. Giới hạn của YOLO
- YOLO đặt ra ràng buộc lớn về không gian lên việc dự đoán các bounding box: mỗi grid cell chỉ được dự đoán 2 boxes và một class (object) duy nhất. Vì thế, ràng buộc này sẽ bộc lộ nhược điểm khi gặp grid cell có nhiều hơn một object, đặc biệt là các object nhỏ chứa trọn trong một grid cell. YOLO sẽ gặp khó khăn trong việc dự đoán các object nhỏ và xuất hiện gần nhau hoặc theo nhóm, ví dụ như một đàn chim, vì khi đó sẽ có thể có nhiều hơn hai con xuất hiện trong cùng một grid cell, và YOLO1 sẽ không thể dự đoán được hết số lượng các con chim xuất hiện trong grid cell đó do giới hạn về số lượng bounding boxes được dự đoán.
- Vì YOLO học cách dự đoán bounding boxes từ dữ liệu nên nó sẽ gặp khó khăn trong việc generalize đến các objects có aspect ratio mới hoặc bất thường. Mô hình này cũng sử dụng feature khá thô (relatively coarse features) trong việc dự đoán bounding boxes, do kiến trúc của YOLO có nhiều downsampling layers từ các bức ảnh đầu vào.
- Hàm loss function coi sai số là như nhau đối với bounding boxes nhỏ và bounding boxes lớn. Cụ thể là, sai số nhỏ trong box lớn thường sẽ không mang ảnh hưởng lớn, trong khi sai số nhỏ trong một box nhỏ sẽ có tác động lớn hơn nhiều lên giá trị IOU. Hầu hết sai số trong YOLO đến từ việc định vị vật thể không chính xác.
4. Kết quả
4.1. VOC PASCAL 2007
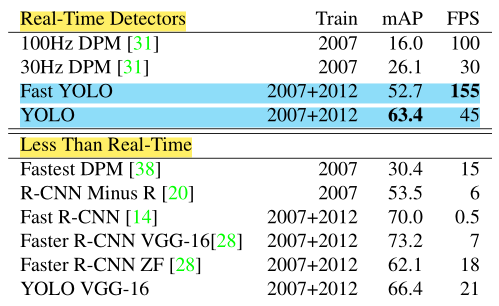
Ta so sánh kết quả thực thi của YOLO với các hệ thống detection khác trên tập dữ liệu PASCAL VOC 2007 với các hệ thống real-time khác ở thời điểm đó.
- YOLO có tốc độ xử lý real-time là 45 FPS với mAP đạt 63.4 – cao nhất trong các hệ thống real-time.
- FAST YOLO đạt được tốc độ real-time cao nhất với 155 FPS và độ chính xác đạt 52.7 mAP – giảm đi 10 mAP so với YOLO.
- Ngoài ra, YOLO vẫn còn đứng sau Faster R-CNN với độ chính xác đạt 70 mAP.
Chi tiết xin mời xem ở bảng bên dưới:
Ta sẽ xem xét kỹ hơn sự khác biệt giữa YOLO và các hệ thống detection hàng đầu khác bằng việc phân tích kết quả trên tập dữ liệu VOC 2007. Ta sẽ so sánh YOLO với Faster R-CNN. Hình bên dưới là sự phân tích sai số giữa Faster R-CNN với YOLO:
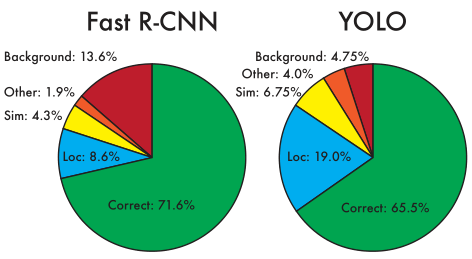
Ta có thể thấy YOLO gặp khó khăn trong việc định vị vật thể một cách chính xác (sai số 19.0%), nó lớn hơn tất cả các loại sai số khác của YOLO cộng lại. Faster R-CNN có localization error nhỏ hơn (8.6%) nhưng nó có nhiều background error hơn (13.6%), gấp gần 3 lần so với YOLO (4.75%).
Nhờ vào việc phân tích sai số ở trên, ta có thể kết hợp YOLO với Faster R-CNN để đạt được độ chính xác cao hơn. Ta sẽ sử dụng YOLO để loại bỏ background từ Faster R-CNN để đạt được hiệu quả cao hơn. Cụ thể là, với mỗi bounding box được dự đón từ Faster R-CNN, ta kiểm tra xem YOLO có dự đoán một box tương tự không. Kết quả ở bảng bên dưới:
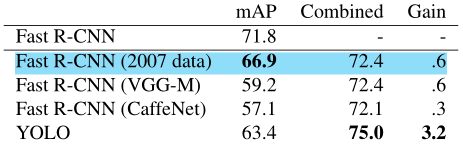
Mô hình Faster R-CNN có kết quả dự đoán cao nhất là 71.8 mAP trên tập dữ liệu test VOC 2007. Khi kết hợp với YOLO, độ chính xác tăng lên đến 75.9%, cao hơn 3.2%.
4.2. VOC PASCAL 2012
Trên tập dữ liệu test VOC 2012, YOLO đạt độ chĩnh xác là 57.9% mAP, thấp hơn so với các phương pháp hàng đầu khác (xem chi tiết ở bảng bên dưới), vì nó gặp khó khăn trong việc dự đoán các vật thể nhỏ. Trong khi đó, mô hình Faster R-CNN + YOLO đạt được độ chính xác hàng đầu với 70.7% mAP.
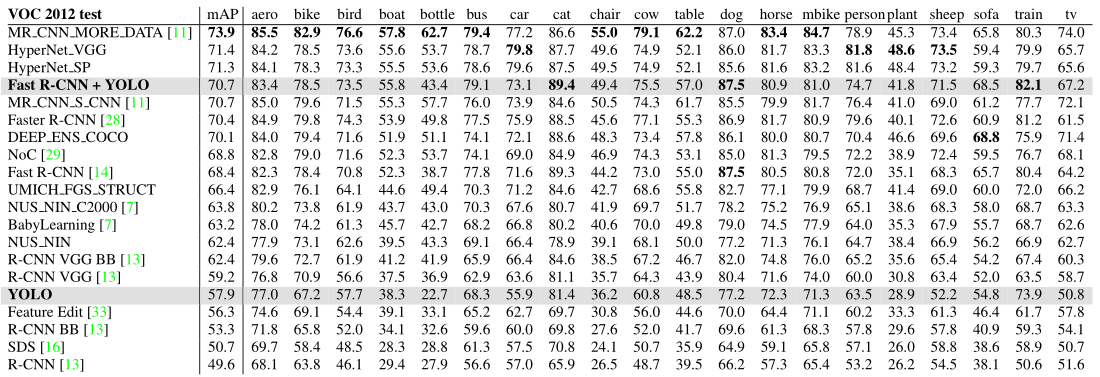
4.3. Artwork
Ta so sánh YOLO với các hệ thống detection khác trên các tập dữ liệu Picasso và People-Art – đây là hai tập dữ liệu cho việc kiểm tra việc phát hiện người trên tranh vẽ.
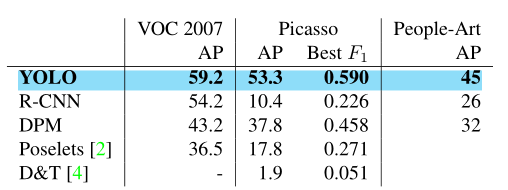
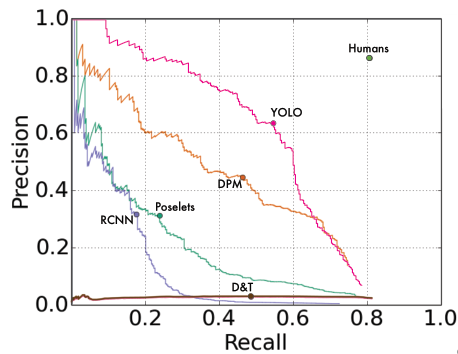
Ở lĩnh vực này, YOLO cũng cho kết quả tốt hơn hẳn so với những phương pháp khác – AP của nó giảm ít hơn so với các phương pháp khác khi áp dụng vào 2 tập dữ liệu tranh vẽ. Hình dưới là đồ thị đường cong Precision-Recall trên tập dữ liệu Picasso với các phương pháp khác nhau.
5. Kết luận
Đây là bài viết giới thiệu và trình bày chi tiết về phiên bản đầu tiên của YOLO, còn được gọi là YOLOv1. Đây là một mô hình dễ dàng xây dựng và có thể được huấn luyện trực tiếp trên toàn bộ bức ảnh. Không giống các phương pháp dựa vào classifiers khác, nó sử dụng một hàm loss tương ứng trực tiếp với hiệu quả detection và toàn bộ mô hình được huấn luyện một cách đồng thời. Hơn nữa, nó cũng tổng quát tốt đến những lĩnh vực mới, giúp nó trở nên lý tưởng cho việc ứng dụng.
6. Tài liệu tham khảo
- You Only Look Once: Unified, Real-Time Object Detection
- Review: YOLOv1 — You Only Look Once (Object Detection)
- YOLO series] p1. Lý thuyết YOLO và YOLOv2
- Official YOLOv1 Webpage
Like và follow fanpage của Pixta Việt Nam để cập nhật các thông tin công nghệ hữu ích nhé!
Tác giả/Writer: Nguyễn Duy Hảo
