
Face Inpainting: Phương pháp khôi phục lại phần bị xoá trên hình ảnh
Giới thiệu
Face Inpainting là việc khôi phục lại cái khu vực hình ảnh đã bị xóa (masked / corrupted) trên khuôn mặt trong khi vẫn giữ được sự hài hòa của tổng thể bố cục. Các phương pháp gần đây thường dựa vào các mô hình được huấn luyện trên một tập dữ liệu lớn và đưa ra các dựa đoán về từng điểm ảnh trong khu vực cần khôi phục. Tuy nhiên, việc thiếu sự kiểm soát trong quá trình dự đoán, cùng với bản chất phức tạp về mặt chi tiết, khiến cho các khuôn mặt tạo ra có thể bị biến dạng kỳ lạ.

Khôi phục lại khuôn mặt sử dụng RunawayML – Stable Diffusion v1.5
Để giải quyết vấn đề này, một phương pháp khác đã được Wuyang Luo et al. giới thiệu, sử dụng một mô hình tạo sinh kết hợp cùng với trích xuất chi tiết hợp lý từ hình ảnh tham chiếu, nhằm khôi phục lại các chi tiết thiếu xót một cách hài hòa và hợp lý. Cùng tìm hiểu tổng quan phương pháp đó trong bài viết hôm nay!
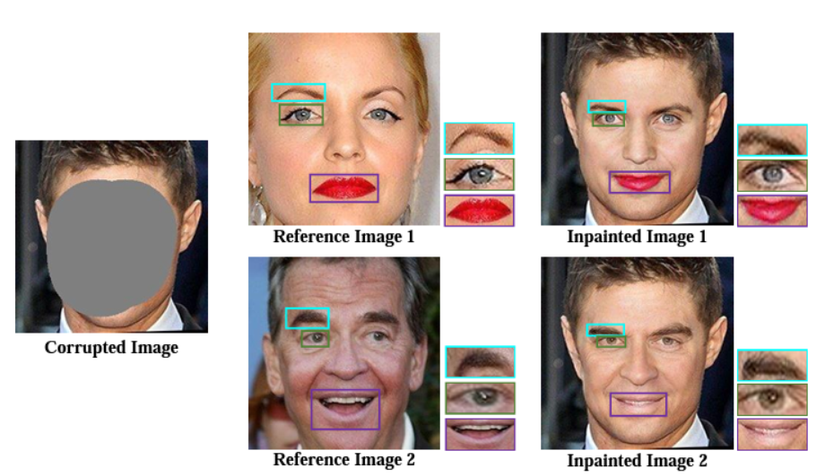
Khôi phục lại khuôn mặt sử dụng mô hình RefFaceInpainting
1. Một số kiến trúc sử dụng trong việc Face Inpainting
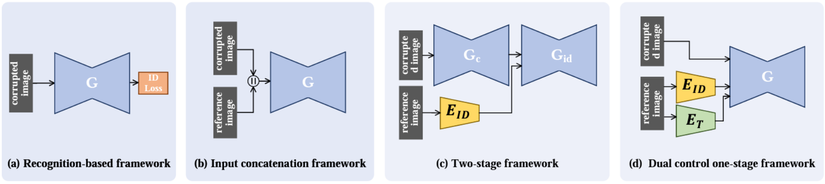
- Kiến trúc Recognition-based: Đầu vào sẽ chỉ có ảnh bị corrupted, mô hình sẽ học cách khôi phục lại ảnh hoàn chỉnh.
- Kiến trúc Input concatenation: Đầu vào sẽ bao gồm cả ảnh bị corrupted và ảnh tham chiếu (chồng ma trận).
- Kiến trúc Two-stage: Kiến trúc này kết hợp giữa việc Inpainting và hoán đổi khuôn mặt
- Kiến trúc Dual control one-stage: Đây là kiến trúc được tác giả Wuyang Luo et al cùng với các mô hình, sử dụng nhằm điều khiển các đặc tính cũng như chi tiết được trích xuất từ hình ảnh tham chiếu, nhằm khôi phục lại hình ảnh bị corrupted.
2. Tổng quan mô hình
Ý tưởng
Với mục đích kiểm soát đầu ra của mô hình, giải pháp sẽ đập hình ảnh tham chiếu ra thành 2 phần thông tin: thông tin tổng quát và thông tin chi tiết. Sử dụng những thông tin trên, mô hình sẽ dần chỉnh sửa hình ảnh đầu ra tương ứng.
Mô hình
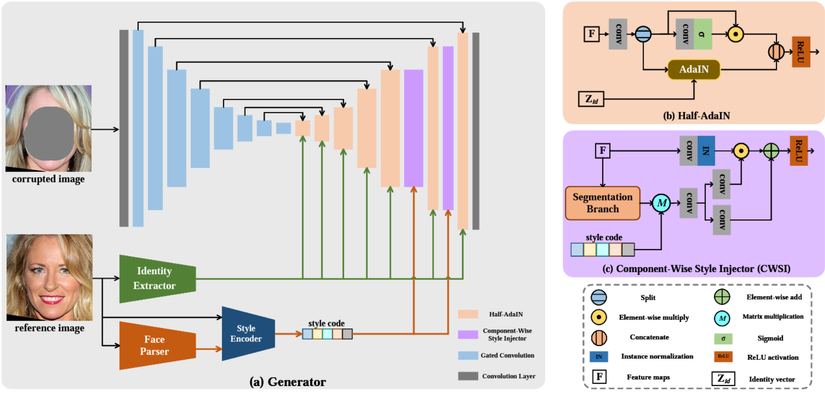
Sơ đồ tổng quan thiết kế
Đầu vào của mô hình sẽ bao gồm một hình ảnh đã bị corrupted và một hình ảnh tham chiếu, chúng ta sẽ lần lượt gọi là hình ảnh C và R. Hình ảnh R sẽ được đi qua 3 modules Identity Extractor và Face Parser và Style Encoder để tạo ra các thông tin dẫn đường cho quá trình khôi phục lại hình ảnh C. Hình ảnh C sẽ trải qua một quá trình nén thông tin (màu xanh) tạo ra Feature Map (F), và tái tạo lại (màu da người) với sử chỉ dẫn đuọc tạo ra bởi hình ảnh R. Ngoài ra, tác giả cũng sử dụng thêm các mạng phân biệt, hiểu nôm na như các “giám khảo” phán xét kết quả do mô hình tạo ra, cụ thể như sau:
- SN-PatchGAN: Đánh giá tổng quan kết quả đầu ra.
- 3 Mạng phân biệt khác được dùng để đánh giá các vùng khác nhau trên khuôn mặt (2 mắt và miệng) giúp mô hình tổng hợp được các chi tiết nhỏ.
3. Các thành phần
Thành phần kiểm soát đặc trưng
- Ở đây, chúng ta sẽ sử dụng một mạng nhận diện khuôn mặt (ArcFace) nhằm trích xuất ra các đặc trưng của khuôn mặt. Các đặc trưng này sẽ loại bỏ các yếu tố về dáng, ánh sáng và cảnh quan xung quanh.
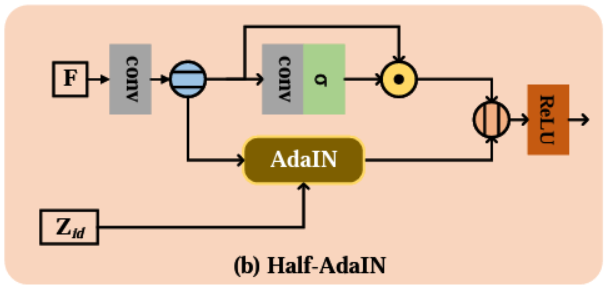
- Half-AdaIN: Như chúng ta có thể thấy ở sơ đồ tổng quan, Half-AdaIN được sử dụng để đưa các đặc trưng của ảnh tham chiếu vào quá trình khôi phục lại ảnh bị corrupted. Half-AdaIN được cải tiến từ AdaIN khi ma trận đặc trưng F thay vì đi thẳng qua module AdaIN, sẽ được tách làm hai phần, kết hợp cùng thông tin đặc trưng của ảnh tham chiếu để tổng hợp lại sau đấy. Điều này là vì AdaIN có thể vứt hết thông tin từ Feature Map F.
Thành phần kiểm soát chi tiết
- Để nắm bắt được các thông tin chi tiết trên khuôn mặt là một công việc phức tạp do bản chất kích thước nhỏ và đa dạng chi tiết, do đó chúng ta sẽ tập trung vào 5 phân vùng chính trên khuôn mặt: Mắt trái, phải, lông mày trái, phải, và môi. Để kiểm soát các chi tiết, chúng ta sẽ tập trung vào việc trích xuất các chi tiết trên các vùng này.
- Style Encoder: Đầu tiên, một mô hình face-parsing sẽ được tận dụng để trích xuất ra bản đồ phân đoạn ảnh (segmentation map). Sau đó, 5 phân vùng trên sẽ được xác định trên bản đồ này, và rút ra được ma trận mã hóa phong cách (style encoding) tương tự như SEAN với kích cỡ 512. Ma trận Style Code này sẽ nắm trong mình các thông tin về chi tiết trên 5 phân vùng khác nhau của khuôn mặt.
- Component-wise Style Injector (CWSI):
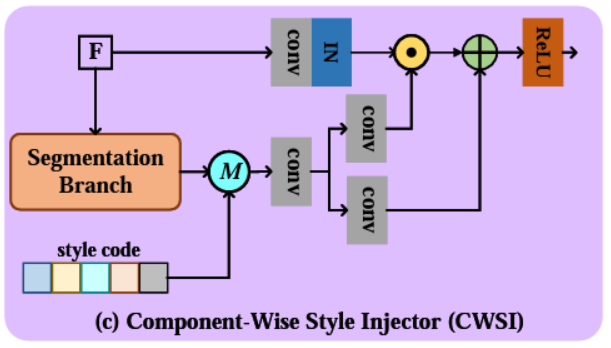
Thành phần này sẽ được sử dụng để đẩy các chi tiết vào Feature Map F trong quá trình táo tạo. Tương tự như thành phần Half-AdaIN, ở đây F cũng được đi vào hai nhánh. Ở Segmentation Branch, tương tự như Style Encoder, nhánh này cũng sử dụng face-parsing để tạo ra segmentation map, chúng ta sẽ lựa chọn 5 phân vùng đã được xác định. Một cách dễ hiểu thì, Segmentation Branch sẽ giúp chúng ta xác định các phân vùng cần được “vẽ” thêm thông tin vào và Style Code chính là ma trận chứa các thông tin được dùng để “vẽ” tương ứng với các phân vùng.
Huấn luyện
Cùng với hai thành phần trên, mô hình sẽ vẽ phác họa ra được khuôn mặt dựa trên các đặc trưng nổi bật của khuôn mặt, sau đó bổ sung các chi tiết còn thiếu vào năm phân vùng khác nhau của khuôn mặt.
Có thể thấy rằng, việc bổ sung chi tiết nắm một cách chính xác đóng vai trò quan trọng trong việc đảm bảo tính hài hòa, tính “real” của khuôn mặt. Do đó, tác giả đề xuất một quy trình huấn luyện ba modes (TMT) nhằm không chỉ cải thiện khả năng Inpaiting, mà còn cải thiện khả năng đưa ra hướng dẫn bổ sung chi tiết của mô hình thông qua việc huấn luận 2 modes còn lại.

Điểm khác biệt giữa các modes nằm ở cách mô hình “che” đi hình ảnh như thế nào, được thể hiện qua hình ảnh sau:

4. Kết quả
Mô hình cho kết quả “real” hơn các mô hình cũ

Kết quả định tính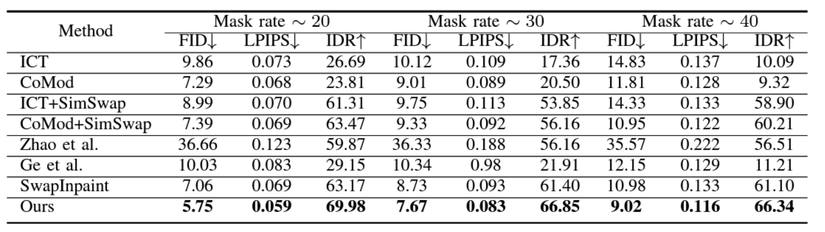
Kết quả định lượng
Việc sử dụng các thành phần giúp cải thiện kết quả mô hình

Tóm lại, việc không sử dụng CWSI không đem lại các cải thiện quá nổi bật, tuy nhiên khi tập trung vào các chi tiết ở xung quanh mắt, môi, lông mày, có thể chúng ta vẫn có thể quan sát được những điểm cải thiện.
Kết hợp chéo các khuôn mặt

Có thể thấy rằng kết quả đưa ra khá thuyết phục về mặt cảm tính.
Các trường hợp thất bại

Có thể thấy rằng các trường hợp thất bại đa phần nằm ở các góc hiếm gặp như nhìn ngang, cúi xuống,… Bộ dữ liệu được sử dụng là CelebA chủ yếu chứa hình ảnh khuôn mặt ở góc thẳng, do đó việc vẽ lại các khuôn mặt ở các góc quá đà như này vẫn còn là một bài toán khó.
5. Kết luận
Trong bài viết này, chúng ta đã cùng nhau tìm hiểu một cách tổng quan về cách một mô hình tái tạo khuôn mặt sử dụng hình ảnh tham chiếu. Bằng cách thiết kế một cách thông minh các thành phần như Half-AdaIN và CWSI, tác giả đã có thể kiểm soát cũng như bổ sung chi tiết một cách chính xác trong quá trình tái tạo. Tuy nhiên, mô hình vẫn tồn tại điểm yếu liên quan đến góc khuôn mặt như đề cập ở trên và hy vọng rằng bài toán này sẽ được giải quyết thông qua các bài báo trong tương lai!
6. Tài liệu tham khảo
- Wuyang Luo, Su Yang, & Weishan Zhang. (2023). Reference-Guided Large-Scale Face Inpainting with Identity and Texture Control.
- Z. (2019, May 18). GitHub – zllrunning/face-parsing.PyTorch: Using modified BiSeNet for face parsing in PyTorch. GitHub.
- Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, & Thomas Huang. (2019). Free-Form Image Inpainting with Gated Convolution.
- Xun Huang, & Serge Belongie. (2017). Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization.
- Peihao Zhu, Rameen Abdal, Yipeng Qin, & Peter Wonka (2020).
Tác giả: Trần Ngọc Hùng Phong
Tìm hiểu thêm về Pixta Vietnam
🌐 Website: https://pixta.vn/careers
🏠 Facebook: https://www.facebook.com/pixtaVN
🔖 LinkedIn: https://www.linkedin.com/company/pixta-vietnam/
