
Finetuning Stable Diffusion hiệu quả với LoRA
Giới thiệu
Có thể nói IG là vua của mọi nghề.
Ngành Image Generation Việt Nam hiện nay ở đầu của sự phát triển. Có thể nói IG là vua của các nghề. Vừa có tiền, vừa có quyền. Vừa kiếm được nhiều $ lại vừa được xã hội trọng vọng.
Và đi cùng với sự phát triển của generative AI nói chung và image generation nói riêng, Stable Diffusion đóng vai trò không hề nhỏ trong việc đưa công nghệ đến gần hơn với cộng đồng. Gọi khả năng ứng dụng của Stable Diffusion là cái ghế, vì nó không phải bàn. Bạn có thể dùng Stable Diffusion để tạo app alime hóa ảnh như Loopsie, làm phim hoạt hình như Artisto, gen ảnh để bỏ vào slides mai lên lớp thuyết trình, tạo ảnh quảng cáo cho sản phẩm của công ty hoặc ướm thử một bộ quần áo trên mạng nào đó lên ảnh bản thân xem có hợp không vì giá nó bằng 30 bát phở lận.
Nếu là người quan tâm đến Stable Diffusion hay các model gen ảnh, chắc hẳn các bạn đã không còn cảm thấy xa lạ với LoRA. Cho dù sinh sau đẻ muộn, LoRA đã bỏ xa cả Dreambooth và Textual Inversion trong cuộc đua chiếm lấy tình yêu của cộng đồng gen ảnh, thống trị các nền tảng train model gen ảnh với sự vượt trội trong thời gian train và kích thước checkpoint. Biểu đồ dưới từ Google Trends là minh chứng rõ ràng nhất cho sự áp đảo của LoRA (đường màu xanh) so với Dreambooth (đường màu đỏ) và Textual Inversion (đường màu vàng).
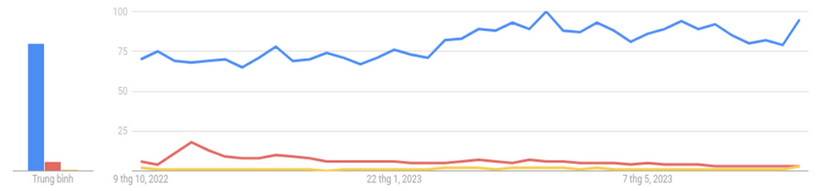
Vậy điều gì đã giúp cho LoRA vượt xa hai đồng nghiệp và trở nên được yêu thích đến vậy? Hãy cùng mình khám phá, tìm hiểu về ý tưởng và những gì LoRA có thể đem lại nhé.
Bối cảnh ra đời
Khác với nhiều người tưởng rằng LoRA là phương pháp sinh ra để tối ưu quá trình training Stable Diffusion, LoRa hay Low-Rank Adaptation vốn bắt nguồn từ những cố gắng train các mô hình ngôn ngữ lớn (Large Language Model – LLM).
Ngày nay, fine-tuning đang dần trở nên phổ biến như một phương pháp hiệu quả để train các mô hình deep learning với ít data nhưng vẫn cho ra kết quả tốt. Do chi phí và tài nguyên bỏ ra tỷ lệ thuận với độ lớn của mô hình, có thể nói các công ty ngày càng phụ thuộc vào pretrained weight. Tuy nhiên, khác với một số kiến trúc đặc trưng như Convolution networks, Attention mechanism (linh hồn của LLMs) không cho phép các mô hình ngôn ngữ freeze toàn bộ layer trước và chỉ train một vài layer sau cùng. Chính vì thế, kể cả khi có thể tận dụng được các checkpoint đã có, việc training các mô hình lớn vẫn là điều gì đó xa xỉ khi mà chúng ta vẫn phải train từng ấy parameters cho các downstream task. Thậm chí đối với các công ty lớn, việc retrain lại mô hình sau một khoảng thời gian để cập nhật kiến thức cho model cũng gặp phải rào cản chi phí và vấn đề lưu trữ.
Trước khi LoRA ra đời, Adapter và Prefix tuning cũng đã cố gắng cản thiện các vấn đề trên. Tuy nhiên, Adapter làm tăng độ trễ (latency) khi infer model, trong khi Prefix tuning lại khiến cho model khó tối ưu hơn, hai giải pháp này không phải những phương án tốt trong việc training LLM. Để đọc thêm về các phương pháp finetuning LLM hiệu quả, các bạn có thể tìm đọc thêm về Parameter Effcient Fine-Tuning (PEFT).
Vậy LoRA hoạt động thế nào?
LLM – đối tượng chính của LoRA – hoạt động chủ yếu dựa trên Attention mechanism. Đây là kỹ thuật để các mô hình ngôn ngữ có thể tập trung vào các phần khác nhau của câu để hiểu được đúng ý nghĩa của cả câu. Chúng ta sẽ đi sâu hơn vào Cross attention và bạn có thể đọc bài viết chi tiết tại đây: https://viblo.asia/p/finetuning-stable-diffusion-hieu-qua-voi-lora-aNj4vxeqL6r
LoRA và Stable Diffusion
Ừm,… Nghe thì cũng hay đấy, nhưng mà lấy đâu ra Attention trong Diffusion? Chẳng lẽ chỉ áp LoRA cho đoạn Text encoder thôi ư? Thực ra là không. Attention mechanism – cụ thể là Cross attention – còn được gắn vào các model Unet bên trong Stable Diffusion.
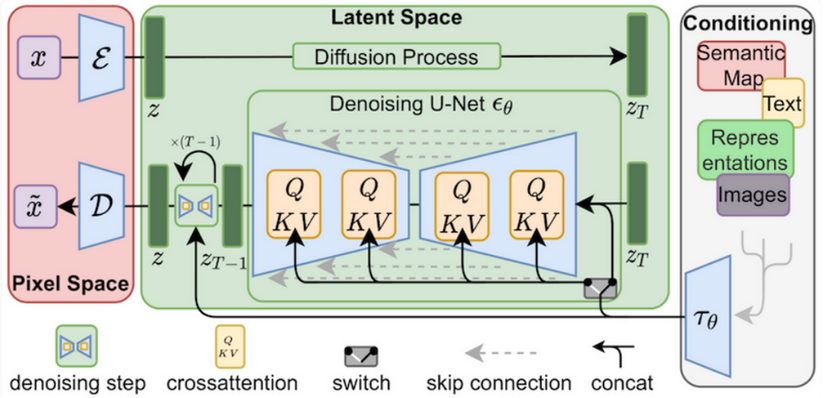
Trong quá trình denoise của Stable Diffusion, Cross attention được sử dụng khéo léo để chọc các thông tin từ prompt vào, hướng cho model gen ra các ảnh như theo yêu cầu. Kéo bài viết lên trên một chút, prompt ở đây sẽ đươc encode và đóng vai trò như Query, trong khi representation của ảnh trong latent space sẽ giống như Value và Key. Ứng dụng của LoRA trong Stable Diffusion chính là ở đây.
Mặc dù không được đề cập trong paper nhưng LoRA lần đầu được ứng dụng trong Stable Diffusion bởi Simo Ryu. Từ đó đến nay, các model LoRA được share liên tục trên CivitAI và Reddit, tạo nên một cộng đồng yêu thích gen ảnh lớn mạnh với vô số style ảnh độc đáo và mới lạ.
Sức mạnh của LoRA
Hiểu được ý tưởng rồi, giờ hãy cùng mình điểm qua những lợi ích mà LoRA có thể đem lại, đặc biệt là trong việc training model Stable Diffusion nhé!
- Giảm thiểu tài nguyên tính toán (computing resource): Chắc chắn rồi. Sinh ra với sứ mệnh khả thi hóa quá trình training ở điều kiện vừa và thấp, người dùng giờ đây chỉ cần bật google colab thay vì các card đồ họa siêu cấp vip pro như A100 hay RTX4090 (Google colab còn không cần thuê Pro cơ =D).
- Lưu trữ và chuyển đổi task dễ dàng: Nếu như ngày trước mỗi model Stable Diffusion cần cả chục GB để lưu thì nay chỉ vài MB là đủ để bạn thay đổi hoàn toàn style của bức ảnh. Việc có kích thước file nhỏ không chỉ giúp chúng ta lưu trữ được nhiều model mà còn giúp việc download/upload trở nên dễ dàng hơn đáng kể.
- Sử dụng được chung với nhiều phương pháp khác: Mặc dù không được để ý nhiều nhưng LoRA có thể được dùng chung với các cách finetuning khác như Prefix tuning hay Dreambooth. Việc sử dụng chung với các phương pháp khác có thể khắc phục một số hạn chế của LoRA.
Kết quả là bây giờ với base model của Stable Diffusion có sẵn trong máy, bạn chỉ cần dạo quanh một vòng Reddit/CiviAI, nheo mắt ngắm xem style nào ưng mắt và tải thêm vài chục MB cho model LoRA. Giờ bạn có thể gen ảnh waifu của mình với đủ loại tư thế, gen ảnh Superman theo phong cách anime, gen ảnh của bản thân theo style Gigachad,… Nghe bánh cuốn đấy nhỉ? Nhưng mà người yêu mình không thích. Người yêu mình thích cún, nên mình sẽ demo thử vài ảnh cún theo nhiều style khác nhau nhé.

Tò mò về Hà Nội vào năm 3069? Hãy dùng LoRA.
Ao ước nhìn thấy Emma Watson dưới nét vẽ của Gosho Aoyama? Hãy dùng LoRA.
Mong muốn nhìn thấy thêm các tuyệt tác theo phong cách của cố họa sĩ Picasso? Hãy dùng LoRA.
Với những người làm computer vision, LoRA nói riêng và Stable Diffusion nói chung cũng có thể là công cụ hữu hiệu trong việc generate data, giúp tăng đáng kể accuracy và performance của model. Tất cả những gì chúng ta cần làm là nhặt một vài bức ảnh rồi bật YouTube xem các pháp sư dạy train trên Colab hoặc Local.
Thế LoRA là phương pháp finetune toàn năng rồi phải không?
Không. Tuyệt vời là thế nhưng LoRA cũng có những hạn chế riêng của mình, bao gồm:
- Không thể tự do chọn các adapter khác nhau cho các sample khác nhau cho cùng một batch. VD như 1 batch của bạn có 10 prompt gen ảnh idol: 2 prompt đầu style anime, 4 prompt sau sinh theo phong cách vẽ của Picasso, 4 prompt cuối cùng sinh theo kiểu truyện tranh Mỹ, thì rất tiếc là không được.
- Cơ chế hoạt động khoa học của LoRA finetuning vẫn còn chưa rõ ràng.
- Không phù hợp cho large-scale training: LoRA chỉ mạnh để dạy cho model gen ảnh với style khác nhau. Với các concept phức tạp (một nhóm người, nhiều nhân vật mới, …), sử dụng các phương pháp finetune khác như Dreambooth hoặc finetune thông thường sẽ có kết quả tốt hơn.
Kết luận
Trí tưởng tượng của chúng ta đôi khi bị ngăn cách với hiện thực bởi khả năng vẽ của bản thân (như mình 😌, vẽ cái máy bay không khác gì con cá). Giờ đây với LoRA, vách ngăn ấy đã mẻ đi nhiều phần. Việc còn lại của chúng ta là nhón chân bước qua cái vách ấy và tận dụng sức mạnh của image generation trong các công việc sáng tạo liên quan đến hình ảnh. Mình hy vọng bài viết đã giải thích được cho các bạn cơ chế hoạt động và vai trò của LoRA đối với Stable Diffusion. Nếu có góp ý hay câu hỏi gì cho mình, đừng ngần ngại comment ở phía dưới. Mình sẽ cố gắng phản hồi trong thời gian sớm nhất. Cảm ơn bạn vì đã đọc đến những dòng cuối cùng này 😍
Tham khảo
https://arxiv.org/abs/2106.09685
https://github.com/cloneofsimo/lora
https://huggingface.co/blog/lora
https://stable-diffusion-art.com/lora/
Tác giả: Lê Nho Bách
Tìm hiểu thêm về Pixta Vietnam
🌐 Website: https://pixta.vn/careers
🏠 Fanpage: https://www.facebook.com/pixtaVN
🔖 LinkedIn: https://www.linkedin.com/company/pixta-vietnam/
