
YOLOv4 – Kỷ nguyên mới cho những mô hình họ YOLO
Trong lĩnh vực Computer Vision, bài toán Object Detection là một bài toán hết sức phổ biến. Như cái tên gọi của nó, mục tiêu của bài toán này là phát hiện và phân loại ra những vật thể tồn tại ở trong khung hình, đây là một bài toán vừa thực hiện tác vụ Classification và Regression (Localization) cùng một lúc. Bài toán đóng một vai trò hết sức quan trọng trong lĩnh vực Computer Vision và có thể ứng dụng vào vô vàn khía cạnh trong đời sống. Vì vậy, nếu có một thuật toán có thể xử lý bài toán này với độ chính xác cao và với tốc độ nhanh thì những công nghệ tương lai như xe không người lái, robot giúp việc thông minh,… sẽ sớm thành hiện thực. Ở trên là một hình ảnh minh họa kết quả của bài toán, rất tuyệt vời phải không?
Mở đầu
Chắc mọi người đã không còn xa lạ gì với cái tên YOLO rồi phải không? YOLOv1, YOLOv2, YOLOv3 xây dựng dựa trên ý tưởng của một one-stage object detection model đã có những thành công đột phá và được mọi người công nhận, vậy tại sao YOLOv4 lại là kỷ nguyên mới của những mô hình này? YOLOv4 cũng được xây dựng dựa trên ý tưởng của YOLOv3 nhưng được thêm cả tỷ những cải tiến mới như BoF, BoS để cải thiện độ chính xác và tốc độ của mô hình. Lý do gọi YOLOv4 là kỷ nguyên mới vì YOLOv4 là mô hình YOLO đầu tiên không được phát triển bởi Joseph Redmon – tác giả của các mô hình YOLO đằng trước, vì tác giả tuyên bố ngưng phát triển YOLO vì một số lý do; thay vào đó những mô hình YOLO sau đó được phát triển bởi những tác giả khác và YOLOv4 được phát triển bởi Alexey Bochkovskiy. Vậy YOLOv4 có gì mới và đột phá? Cùng tìm hiểu ngay tại bài viết dưới đây!
Một số khái niệm cần nắm
Dưới đây là một số khái niệm mọi người cần nắm được trước khi đọc sâu hơn bài viết hoặc quay lại khi gặp khái niệm nào không hiểu, mình sẽ đi qua từng khái niệm một cách ngắn gọn và dễ hiểu. Bắt đầu thôi!!!
Bag of Freebies (BoF)
Bag of Freebies là tập những kĩ thuật hoặc phương pháp mà thay đổi chiến thuật training hoặc chi phí training để có thể cải thiện độ chính xác của mô hình mà không làm tăng chi phí suy luận. Trong thực tế, phần lớn các mô hình CNN đều được huấn luyện offline nên điều này có thể được ứng dụng ở trong phần lớn các kiến trúc mô hình. Có rất nhiều phương pháp thay đổi chiến huật training để cải thiện độ chính xác mô hình mà không làm tăng chi phí suy luận nhưng ở trong bài báo của YOLOv4, tác giả đưa ra 3 chiến thuật chính:
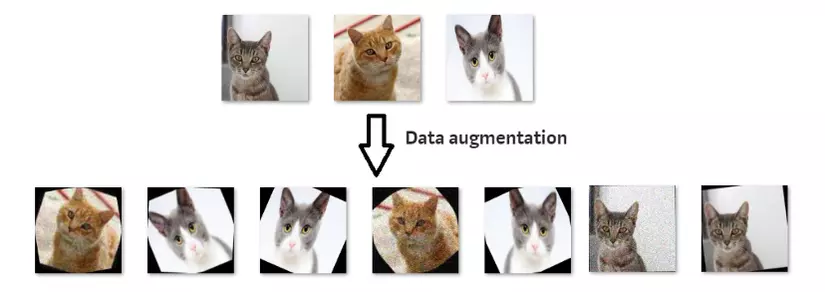
1. Data AugmentationData Augmentation là những phương pháp biến đổi ảnh đầu vào để làm gia tăng thêm độ phong phú của dữ liệu, từ đó model của chúng ta được huấn luyện trên những ảnh này có thể có khả năng chịu nhiễu lỗi tốt hơn. Có rất nhiều phương pháp Data Augmentation như thay đổi trắc quang của ảnh: độ sáng, tương phản, hue, saturation,… ; thay đổi hình học của ảnh: random scaling, cropping, flipping, …; hoặc có thể là vài phương pháp nâng cao hơn như: Random Erase and CutOut, DropOut, Grid Mask, …; thậm chí có thể là kết hợp 2 ảnh bằng phương pháp: MixUp, CutMix,… .
2. Semantic Distribution Bias in Datasets Inherent bias là một mối quan ngại lớn vì nó đên từ sự phong phú trong tập dữ liệu dùng để train model. Nếu phân bố dữ liệu có vấn đề bias, nó có thể kéo quá trình training đến hội tụ đến cực tiểu địa phương và không thể khái quát hóa được. Nhìn chung vấn đề này từ 2 nguyên nhân chính từ tập dữ liệu:
- Data Imbalance giữa các classes
- Trong mạng two-stage, vấn đề này có thể xử lý bằng cách tìm thêm những dữ liệu negative khó và dữ liệu online khó.
- Trong mạng one-stage, người ta có thể dùng focal loss để xử lý vấn đề này.
- Không thể diên giải mối quan hệ của mức độ liên kết giữa các lơp khác nhau với biểu diễn one-hot
- Vấn đề này có thể xử lý bằng cách sử dụng smooth labeling.
3. Objective Function of BBox Regression
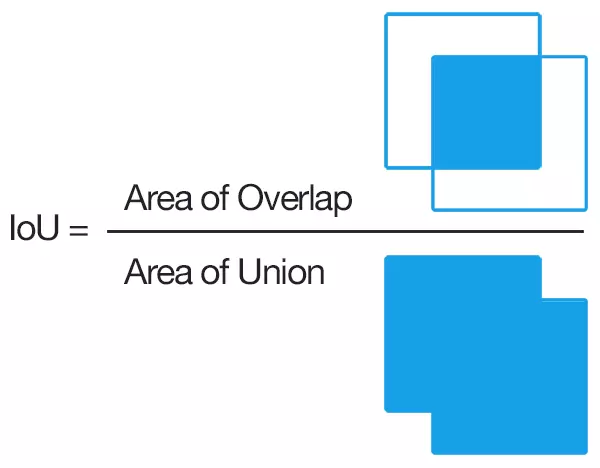
- Trong bài toán Object Detection, hàm mục tiêu (hay còn gọi là hàm lỗi) phải cần được điều chỉnh để phù hợp với đầu ra của bài toán. Một phương pháp cổ điển là dùng hàm Mean Square Error (MSE) để tính toán giá trị sai khác giữa dự đoán của mô hình và ground truth của dữ liệu trên các giá trị là tọa độ điểm tâm (xc, yc) và chiều cao, chiều rộng của Bounding Box. Dĩ nhiên phương pháp này là không tốt, và người ta đưa ra 1 hướng tiếp cận khác là Anchor based approaches. Anchor based approaches là hướng tiếp cận sử dụng độ lệch tương ứng của những điểm này. Một phương pháp kinh điển nhất trong hướng tiếp cận này là IoU loss, tính toán độ trùng của box dự đoán và ground truth box.
Còn rất nhiều phương pháp nữa như GIoU, DIoU, CIoU mình sẽ trình bày ở phần sau.
Bag of Speacials (BoS)
Khác với Bag of Freebies, Bag of Speacials là tập những phương pháp thêm một vài plugin modules và một vài post-processing methods để chỉ tăng thêm chi phí xử lý một chút nhưng cải thiện được kha khá độ chính xác của mô hình. Cụ thể hơn, những plugin modules này giúp tăng thêm một chút thuộc tính của model như mở rộng receptive field (định nghĩa này mình sẽ nói kĩ hơn ở dưới), thêm cơ chế attention, tăng cường thêm khả năng tích hợp, … và post-processing để hiển thị kết quả dự đoán của model (như hình vẽ ban đầu).
Receptive field
Receptive field là kích thước của một vùng trong không gian đầu vào được nhìn thấy bởi 1 pixel output. Không như mang Fully Connected, một node có thể phụ thuộc vào toàn bộ input đầu vào của mạng thì trong CNN, 1 pixel output chỉ phụ thuộc vào 1 vùng của ảnh input, vùng này chính là receptive field. Oke vẫn còn rất khó hiểu đúng không, mình hãy thử nhìn vào hình vẽ trực quan 1 chút nhé: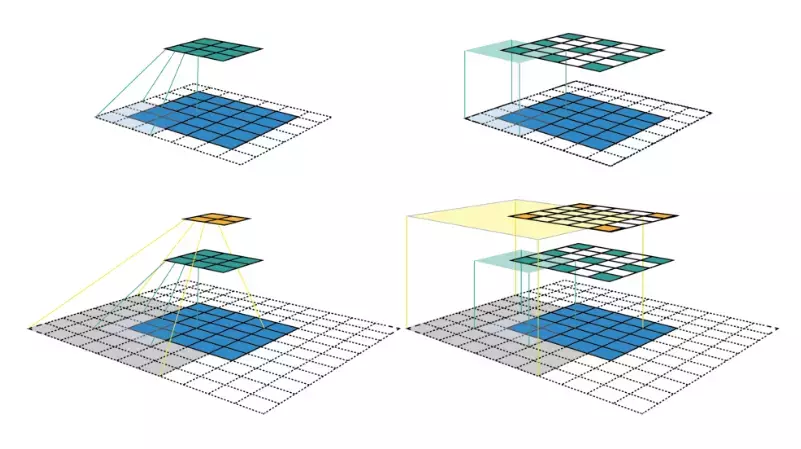
Qua hình vẽ thì ta thấy một pixel ở tầng càng cao thì nó bao phủ được càng nhiều pixel ở những tầng dưới hơn. Dễ hiểu hơn chưa? Vậy thì receptive field để làm gì?
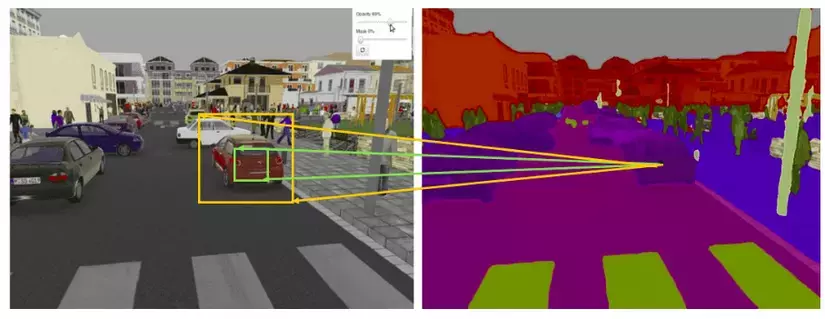
Tưởng tượng bạn đang làm bài toán image segmentation thì ta cần phải phân loại xem 1 pixel thì cần phải tương ứng với class nào, vậy thì điều dễ thấy là điều kiện lý tưởng nhất là mỗi output pixel có một receptive field thât lớn, điều này giúp model không bỏ qua chi tiết quan trọng khi dự đoán. Trong hình bên dưới thì ta dễ thấy là nếu phần pixel phụ thuộc vào phần màu vàng sẽ tốt hơn là phụ thuộc vào phần màu xanh phải không?
Bạn có thể tham khảo bài báo này để tìm hiểu sâu hơn nếu muốn nhé: https://arxiv.org/pdf/1701.04128.pdf
Kiến trúc tổng quan của môt mô hình Object Detection
Nhìn chung một mô hình Object Detection được chia thành 2 thành phần chính là phần Backbone dùng cho feature extraction và một phần còn lại là phần Head dùng để dự đoán và tính toán giá trị lỗi mỗi lần dự đoán.
- Phần Backbone có thể sử dụng những mạng sẵn có được train trên tập ImageNet như VGG, ResNet, DenseNet, … (nếu sử dụng trên những nền tảng có GPU) hoặc SqueezeNet, MobileNet, ShuffleNet (nếu sử dụng trên những nền tảng chỉ có CPU).
- Phần Head được chia làm 2 loại: one-stage và two-stage. Ngắn gọn thì two-stage là những kiểu mạng cổ điển mà quá trình ra output được chia làm 2 phần là localization và classification, trong khi đó one-stage thì gộp 2 quá trình này thành một. Vâng, và đúng là one-stage có khả năng dự đoán nhanh hơn rất nhiều so với two-stage object detection. Những mạng Two-stage phổ biến như : RCNN, FastRCNN, FasterRCNN,… còn những mạng one-stage phổ biến là: YOLO, SDD, RetinaNet,…
- Ngoài 2 phần trên ra thì trong những mạng hiện nay thì nhiều tác giả bổ sung thêm phần Neck. Phần này được thêm vào giữa Head và Backbone để tăng cường sự phong phú và khả năng biểu diễn ngữ nghĩa của các đối tượng được trích xuất cho các đối tượng có hình dạng và kích thước khác nhau. Hình ảnh dưới đây khái quát tổng quan về những thành phần trong mạng object detection.
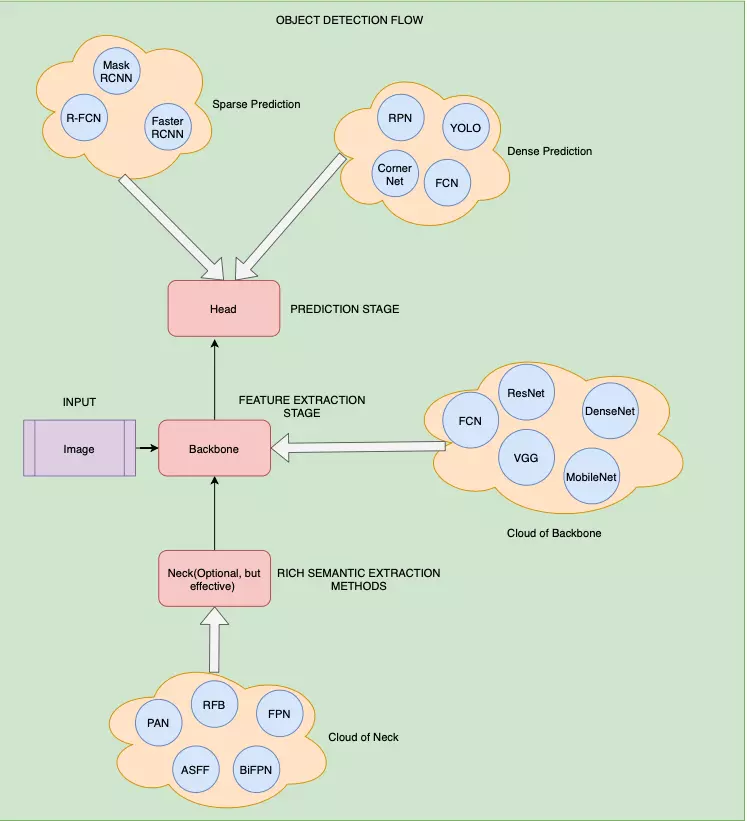
Kiến trúc của YOLOv4
Vậy là mọi người đã hiểu những khái niệm rồi phải không? Vậy mình hãy cùng tìm hiểu xem YOLOv4 sử dụng những gì nhé: Về kiến trúc thì YOLOv4 bao gồm 3 phần chính:
- Backbone: CSPDarknet53
- Neck: SPP (Spatial Pyramid Pooling), PAN (Path Aggregation Network)
- Head: YOLOv3
Ngoài ra, YOLOv4 còn sử dụng những BoF và BoS để tăng tốc quá trình training và cải thiện độ chính xác của mô hình như sau:
- Bag of Freebies (BoF) sử dụng cho phần Backbone:
- CutMix và Mosaic data augmentation
- DropBlock regularization
- Class label smoothing
- Bag of Specials (BoS) sử dụng cho phần Backbone:
- Mish activation
- CSP block
- Multi-input weighted residual connection
- Bag of Freebies (BoF) sử dụng cho phần Detector:
- CIoU-loss
- Cross mini Batch Normalization
- DropBlock regularization
- Mosaic data augmentation
- Seft-Adversarial Training
- Eliminate grid sensitivity
- Multiple anchors
- Cosine annealing scheduler
- Optimal hyperparameters with Genetic Algorithm
- Bag of Specials (BoS) sử dụng cho phần Detector:
- Mish activation
- SPP-block
- SAM-block
- PAN
- DIoU-NMS
Phần sau sẽ đi sâu vào những thành phần ở bên trong YOLOv4 và giải thích kĩ về cách nó hoạt động và nhiệm vụ, vai trò của từng thành phần ở trong mạng.
Nhóm các block, kiến trúc ở trong mạng
CSP Block
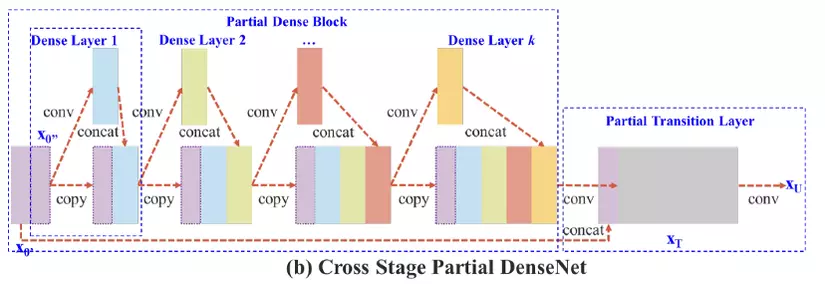
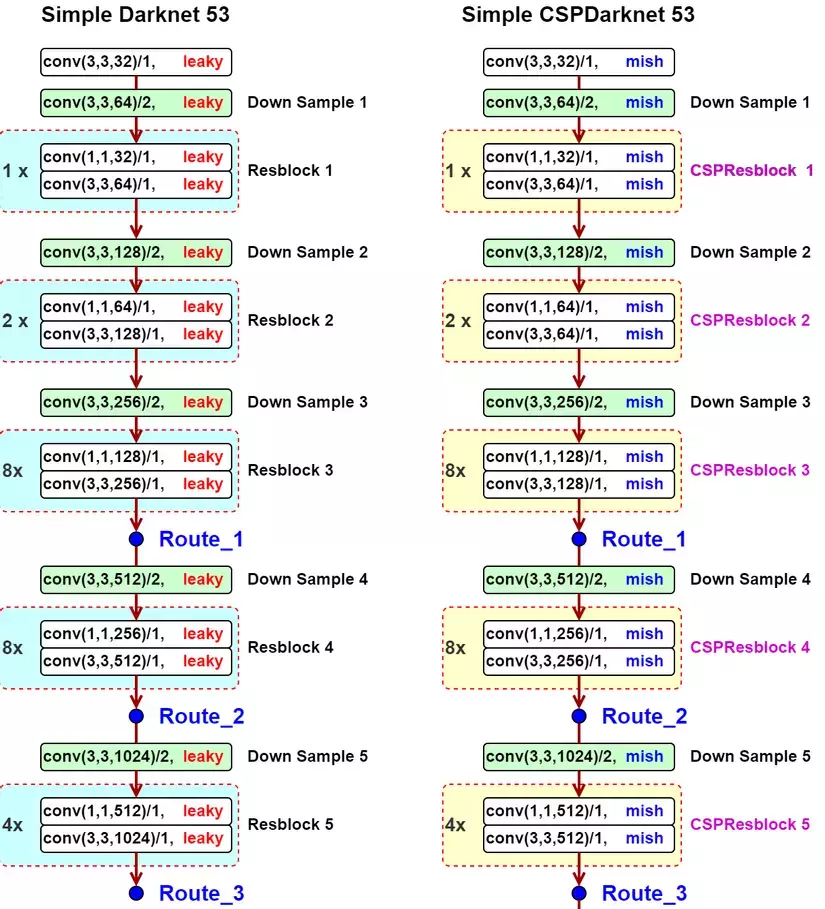
Ta hãy lấy CSPDenseNey là 1 ví dụ. Ý tưởng chính của CSPDenseBlock là tách feature map ra thành 2 phần, một phần sẽ cho đi qua những khối dense block với nhiều dense layer ( bạn có thể tìm hiểu thêm về dense layer tại đây ) và một transition layer; phần còn lại sẽ được kết hợp với với transmitted feature map để mang sang stage tiếp theo. Vì vậy, với điều này thì trong mạng sẽ có 2 luồng gradient và feature map được độc lập với nhau để thực hiện những mục đích riêng. Mạng CSP không chỉ bảo toàn được lợi ích của việc sử dụng lại những feature characteristics của mạng DenseNet mà còn thêm khả năng ngăn chặn lượng thông tin gradient trùng lặp quá mức bằng cách cắt bớt dòng gradient. Nhờ vậy ta có thể tăng tốc quá trình training và còn giảm số lượng tham số cần tính toán để tăng tốc độ inference. Ngoài ra kiến trúc này con có thể áp dụng vào nhiều mạng khác chứ không riêng gi mạng DenseNet, điển hình, trong bài báo tác giả sử dụng mạng CSPDarkNet53 làm mạng Backbone. Mạng này được xây dựng với ý tưởng thay thế Residual Block thành CSPResBlock và thay đổi activation function từ LeakyReLY thành Mish.
Drop Block
Trong bài toán Classification, để tránh hiện tượng Overfitting, người ta thường thêm lớp DropOut nhằm loại bỏ ngẫu nhiên 1 vài neuron ra khỏi quá trình training nhằm mục đích tránh cho các neuron quá phụ thuộc lẫn nhau dẫn đến mạng bị phức tạp. Tuy nhiên ở trong mạng Convolution thì bỏ đi ngẫu nhiên ở một số vị trí trong feature map không hợp lý vì các vị trí cạnh nhau trong feature map có tương quan cao với nhau nên bỏ đi những vị trí random như vậy sẽ không đem lại hiệu quả. Vì vậy DropBlock sẽ bỏ đi nhóm vị trí trong feature map thay vì chỉ bỏ đi một vị trí.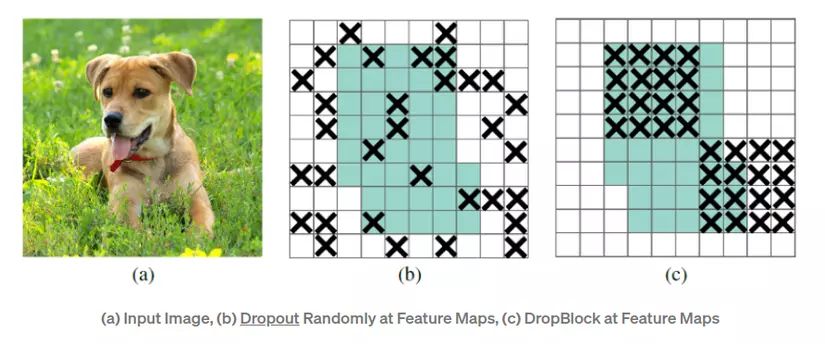
Mish activation function
Trong bài báo, tác giả sử dụng hàm này ở trong mạng, ta cùng tìm hiểu xem nó là gì và tại sao nó được sử dụng nhé !! Tiền thân của hàm Mish này là hàm Swish, hàm Swish có công thức toán học như sau:
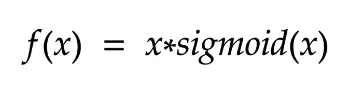
Và có đồ thị như sau:
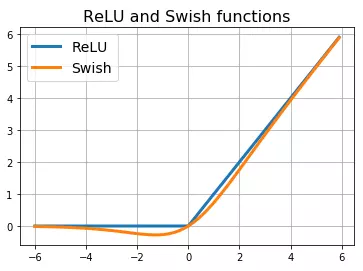
Nhìn chung, hàm Swish đã cải thiện hơn hàm ReLU ở chỗ làm mượt hàm hơn và không bị đột ngột thay đổi ở x = 0 như ReLU, ngoài ra trong hàm ReLU thì toàn bộ giá trị âm thì sẽ đưa giá trị đầu ra là 0 và điều này không tận dụng được những giá trị âm nhỏ vì những giá trị này có thể sẽ đem lại thông tin. Trong hàm Swish thì những giá trị âm lớn thì cũng sẽ đưa ra giá trị bằng 0 vì vậy hàm sẽ vừa lợi dụng được thông tin ở gần giá trị 0 mà còn loại bỏ được những giá trị âm quá lớn. Hơn nữa, Swish còn là hàm không đơn điệu tăng thêm mức độ diễn giải data và học trọng số. Kế thừa những tính chất đó, người ta tạo ra hàm Mish với các tính chất: mượt, liên tục, tự chỉnh lưu, đơn điệu với công thức như sau:
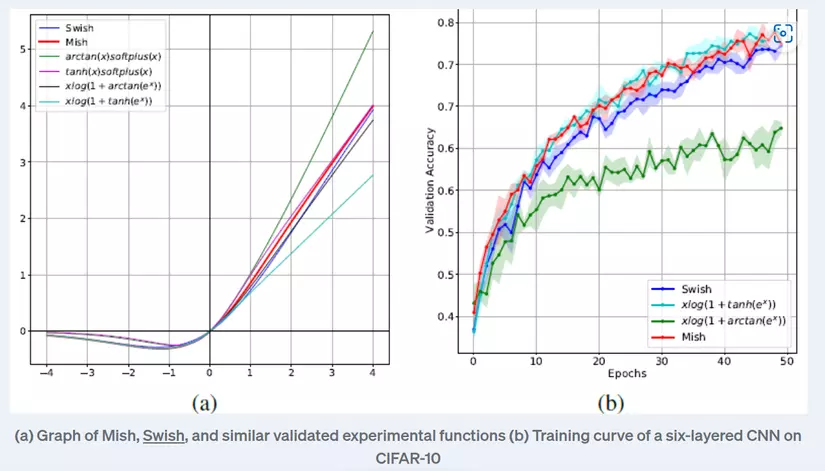
Khi training, hàm Mish có khả năng loại bỏ hiện tượng Dying ReLU, không bị chặn trên, tránh bão hòa, ngoài ra còn có đạo hàm liên tục. Vì những tính chất này, hàm Mish có khả năng tăng tốc quá trình training và hoạt động tốt hơn các hàm kích hoạt các. Hình ảnh sau sẽ là so sánh hàm Mish với các hàm khác
Multi-input weighted residual connection (MiWRC)
SPP Block
Thông thường, trong những tác vụ classification, phần output feature map sẽ được flatten để làm đầu vào cho lớp Fully Connected ở cuối. Tuy nhiên, bằng cách này thì ta phải cố định size của output feature map và điều này gây khó khăn trong việc detect objects trong nhiều kích thước ảnh khác nhau.
Để khắc phục điều này thì người ta cho output feature map đi qua những lớp pooling với kích thước khác nhau trên từng channels của ảnh. Ví dụ ta có ảnh đầu vào có kích thước 512 x 100 x 100 () thì khi đi qua 3 lớp pooling với kích thước kernel là 1×1, 2×2, 4×4 thì SPP sẽ tạo ra 512,4∗512,16∗512 1-D vectors và được concatenated để thành đầu vào cho lớp FC ở cuối. Hơn nữa, với việc sử dụng nhiều kernel với kích thước khác nhau, lớp SPP còn có khả năng tăng cường receptive field, nếu bạn vẫn chưa hiểu receptive field là gì thì bạn có thể xem lại phần 1 của series này
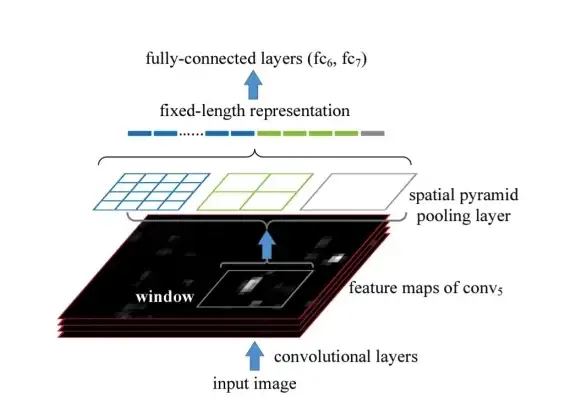
Như vậy, khối SPP được dùng để tạo ra 1-D vector cho lớp FC ở cuối. Tuy nhiên kiến trúc YOLO từ YOLOv2 đã không còn sử dụng lớp FC ở cuối mà thay vào đó là FCNs, vậy YOLOv4 giải quyết vấn đề này như thế nào? YOLOv4 đã chỉnh sửa kiến trúc này một chút, thay vì sử dụng 3 kernal pooling thì YOLOv4 đưa qua những lớp convolutional với kernel có kích thước là 1×1, 3×3, 9×9, 13×13 để tạo ra những feature map với cùng kích thước C x H x W và rồi concatenate chúng lại với nhau tạo thành một khối feature map (4 x C) x H x W. Điều này làm tăng cường receptive field và nhận diện vật thể ở nhiều kích thước khác nhau.
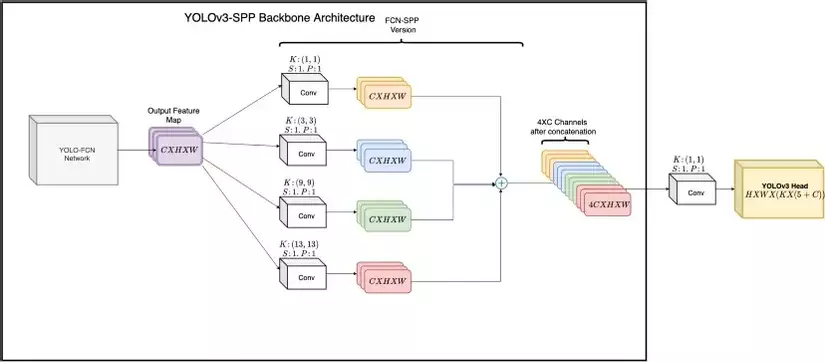
PAN Block
PAN là viết tắt của Path Aggregation Network và một phiên bản cải tiến của FPN (Feature Pyramid Networks). Vậy FPN là gì và PAN có gì cải tiến so với FPN? FPNs rất linh hoạt và hiện nay vẫn còn nhiều kiến trúc sử dụng nó với tác dụng để lưu chuyển và kết hợp những local (low-level) features và global (high-level) features. Nó giúp kết hợp những semantic features đáng giá từ những level cao của pyramid và localization features từ những level thấp hơn để cho kết quả dự đoán cuối cùng. Nhìn chung lớp này có kiến trúc như sau với 2 path là bottom-up pathway và top-down pathway với những lateral connection để kết hợp như sau:
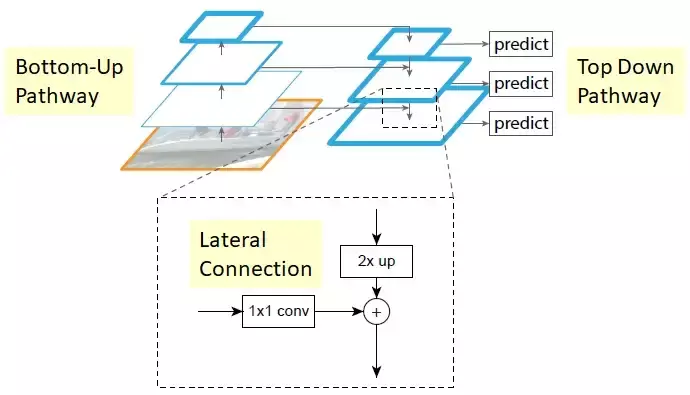
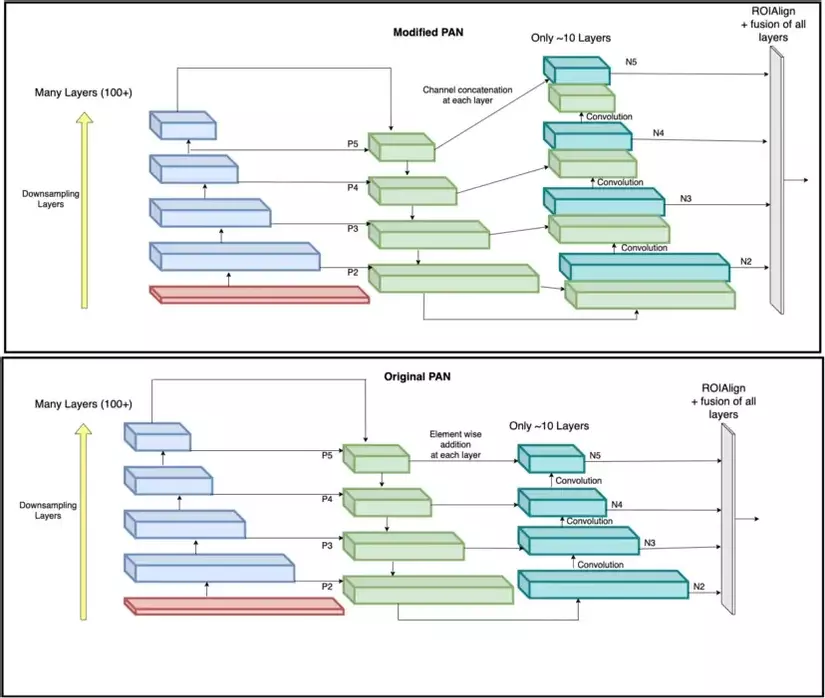
Vậy PAN có gì khác so với FPN, PAN hoạt động cũng giống như FPN tuy nhiên nó thêm 1 bottom-up path để những localization features từ những lớp thấp có thể kết hợp với những semantic features từ lớp cao ở lớp N5 sử dụng shortcut path. Cuối cùng những output feature maps từ lớp bottom-up cuối cùng của pyramid sẽ được kết hợp sử dụng ROIAlign và FC Layers vì vậy toàn bộ những sự thay đổi của feature maps có thể được sử dụng trong quá trình prediction. Ngoài ra trong YOLOv4, tác giả còn thay đỏi khối này bằng cách concatenate feature maps từ 2 level khác nhau để không bỏ lỡ feature nào.
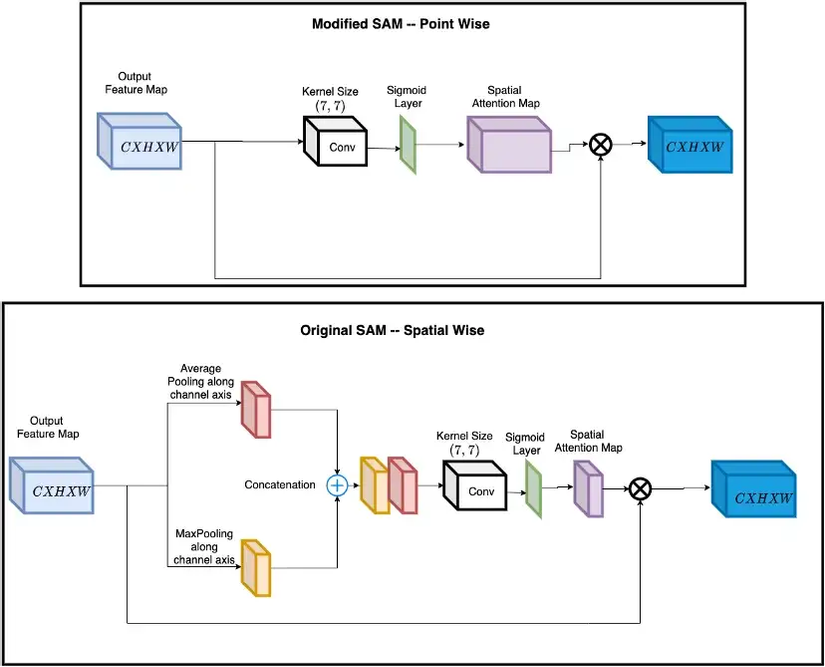
SAM Block
SAM là viết tắt của Spatial Attention Module. Attention modules gần đây đang được sử dụng nhiều trong những mạng CNN để làm mạng tập trung vào những objects có trong ảnh hơn là tập trung về tổng thể. Modules này giúp mạng có thể trả lời câu hỏi where và what để tăng cường weight tập trung vào những thông tin ngữ cảnh xung quanh object và những features quan trọng. Để tìm hiểu sâu hơn về SAM, bạn có thể tham khảo thêm tại đây. Trong YOLOv4, tác giả đã đưa ra một vài chỉnh sửa trong kiến trúc SAM để nó tập trung vào điểm thay vào việc biến đổi feature map bằng cách thêm những lớp average và max pooling. Tác giả sử dụng sigmoid activation function sau lớp CNN để tập trung hẳn vào những thông tin ngữ cảnh của vật thể, những giá trị không có vai trò trong dectection/classification sẽ bị loại bỏ. Cuối cùng là phép element-wise để thêm tham số attention vào trong ảnh.
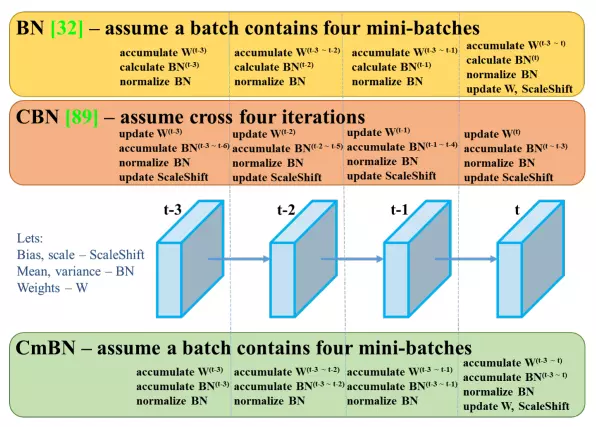
Cross-mini Batch Normalization
CmBN là một phiên bản được sửa đổi của CBN ( Cross Batch Normalization ). Bạn nên đọc qua về Batch Normalization và Cross Batch Normalization trước tại đây. Phiên bản CmBN thì đơn giản là sẽ thu thâp những thông tin thống kê giữa những mini-batches trong một batch.
YOLOv3
YOLOv3 được sử dụng trong YOLOv4 với vai trò là head nghĩa là phần để dự đoán ra bounding box và phân lớp cho bounding box đó. Để tìm hiểu kĩ hơn về cách YOLOv3 hoạt động, bạn có thể đọc bài viết này
Nhóm các features bên ngoài mà tác giả sử dụng
Mosaic data augmentation
Mosaic là môt phương pháp data augmentation mà mixes 4 training images lại với nhau. Điều này cho phép nhận diện vật thể bên ngoài ngữ cảnh của nó. Ngoài ra nó có thể giảm thiểu mini-batch size lớn cho batch normalization.
SAT data augmentation
SAT viết tắt của Seft-Adversial Training là một phương pháp data augmentation mới, thông thường khi thực hiện forward pass của một ảnh qua model ta sẽ thực hiện backward pass để cập nhật weights của model để có thể phát hiện tốt hơn. Tuy nhiên SAT sẽ sửa đổi lại quá trình này và chia thành 2 stages: * Ở stage thứ nhất, mạng neural sẽ thay đổi ảnh gốc thay vì điều chỉnh weights của mạng. Bằng cách này, mạng nơ-ron thực hiện adversarial attack vào chính nó, làm thay đổi hình ảnh ban đầu để tạo ra sự lừa dối rằng không có đối tượng mong muốn trên hình ảnh. * Ở stage thứ hai thì neural network sẽ detect object trên ảnh đã bị thay đổi theo cách thông thường. Ảnh được tạo ra bởi SAT được thể hiện như hình:

Class-label smoothing
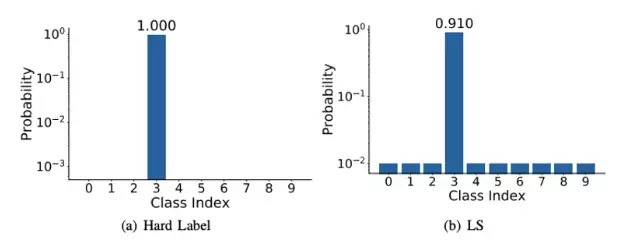
Lớp cuối cùng của môt neural network thường là lớp Fully Connected dùng để dự đoán và đưa ra output. Ở lớp này người ta thường sử dụng softmax để normalize đầu ra và thu được xác xuất dự đoán của từng class. Ở đây, ý tưởng class-label smoothing được đưa ra để tránh việc khi training thì việc sử dụng nhãn là một one-hot vector cứng (nghĩa là chỉ 1 class có giá trị bằng 1 còn lại tất cả classes còn lại có giá trị bằng 0) thì hàm lỗi sẽ khuyến khích việc các class khác nhau trở nên cực kì phân biệt với nhau. Vì vậy người ta bỏ bớt 1 đại lượng từ class chính và thêm vào những class khác với công thức:
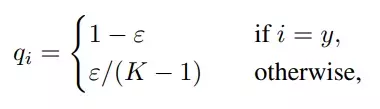
Điều này sẽ làm cho mô hình được khái quát hóa tốt hơn. Phân phối class sẽ trở thành như sau:
Optimal hyper parameter with Genetic Algorithm
Các phương pháp truyền thống để lựa chọn siêu tham số cho mô hình như grid search có thể khó sử dụng vì 3 nguyên nhân. Thứ nhất, không gian tìm kiếm lớn. Thứ hai, không có sự tương quan giữa các tham số. Thứ ba, chi phí xác điểm phù hợp cao. Vì vậy, người ta đã nghiên cứu sử dụng giải thuật di truyền để lựa chọn tham số. Về các hoạt động cơ bản của giải thuật di truyền, các bạn có thể tìm hiểu thêm ở đây. Để áp dụng giải thuật di truyền thì người ta sẽ mã hóa những giá trị siêu tham số thành những đoạn gen và có những phương pháp để đánh giá những bộ tham số (cá thể) thông qua đó lựa chọn ra những các thể tốt và áp dựng những phương pháp tiến hóa như lai ghép, đột biến. Cuối cùng sau 1 số thế hệ thì ta sẽ thu được bộ tham số tốt. Để tìm hiểu sâu hơn về phương pháp này, các bạn có thể tham khảo thêm ở đây
CIoU loss
Như đã giới thiệu ở phần trên, ta có IoU loss bằng cách lấy thương của diện tích phần trùng lặp của 2 bounding box với diện tích hợp của 2 bounding box. Ngoài ra, người ta còn phát triển ý tưởng của loss này thành các loại loss khác như sau:
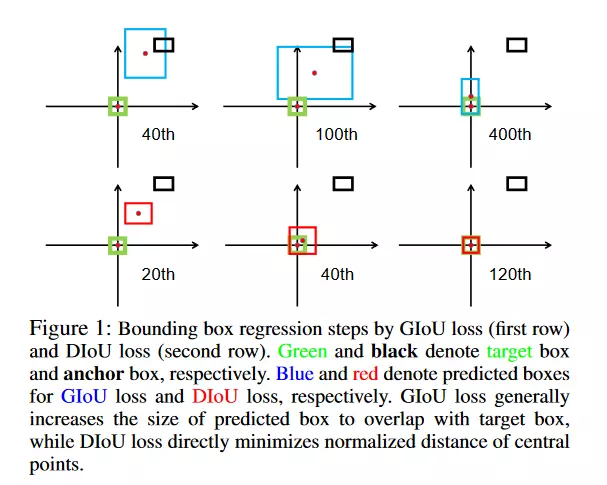
- GIoU (Generalized Intersection over Union)Vấn đề của IoU là khi 2 bounding box không trùng nhau thì mạng sẽ không học được gì vì loss=0. Vì vậy GIoU loss sẽ quan tâm đến những trường hợp không trùng lặp như này. Ý tưởng của GIoU loss là sẽ đưa 2 bounding box không trùng lặp lại gần nhau trong khi IoU loss sẽ không cải thiện gì trong trường hợp này. GIoU loss được thể hiện như hình:
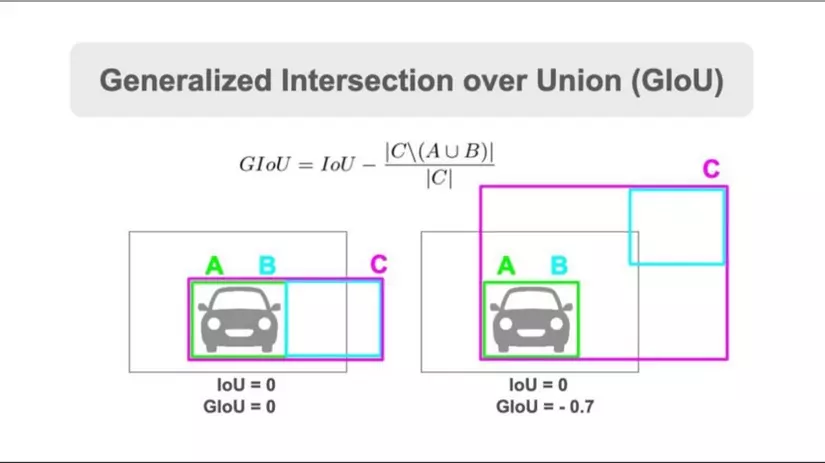
-
DIoU (Distance IoU)
DIoU cũng được sinh ra với lý do tương tự với GIoU loss nhưng nó thêm mối quan tâm về khoảng cách giữa tâm của các bounding box như 1 đại lượng phạt thêm. Bằng cách này thì DIoU loss có tác dụng như GIoU loss nhưng hội tụ sẽ nhanh hơn. DIoU có công thức như sau:
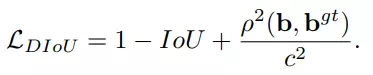
- CIoU (Complete IoU)CIoU loss kế thừa ý tưởng từ những loại IoU loss trên và quan tâm đến 3 độ do chính: Diện tích phần trùng lặp, khoảng cách giữa tâm của các bounding box và tỉ lệ giữa các khung. CIoU loss được thể hiện như sau:
-
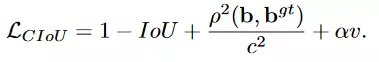
tham số đánh đổi tích cực trong đó các trường hợp trùng lặp được ưu tiên cao hơn so với các trường hợp không trùng lặp và cung cấp thông tin về tính nhất quán của tỷ lệ khung hình. Hai đại lượng này có công thức như sau:
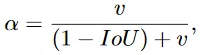
-
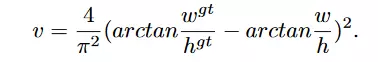
CIoU đạt khả năng hội tụ và độ chính xác cao hơn so với các loại IoU loss khác:
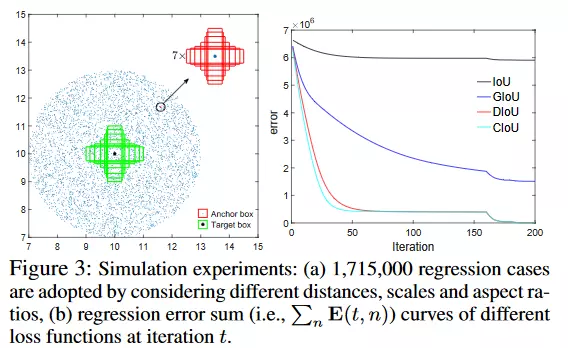
Eliminate grid sentivity
Trong YOLOv3, công thức xác lập bounding box được tính như sau
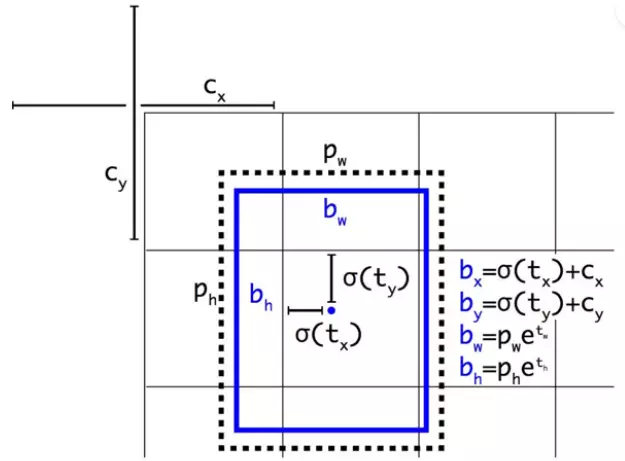
Multiple Anchor
Ở YOLOv3, chỉ những anchor có IoU lớn nhất với ground truth bounding box mới được chọn làm positive anchor và sử dụng trong quá trình training và bỏ qua những anchor khác. Ở trong YOLOv4, người ta sẽ lấy những anchor vượt qua 1 ngưỡng nhất định (cụ thể là có IoU > 0.5) để sử dụng trong quá trình tính loss thay vì bỏ đi. Tuy tác dụng của việc này vẫn chưa được làm rõ trong YOLOv4 nhưng có thể nó sẽ có đóng góp trong việc giảm đi class imbalance giữa background và foreground object.
Consine anneling scheduler
YOLOv4 sử dụng kỹ thuật này để thay đổi learning rate trong quá trình training. Chiến thuật này sẽ làm giảm learning rate theo hàm cos. Ví dụ tổng số batch là T, tại batch thứ t learning rate sẽ được tính như sau:
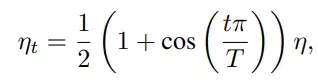
Hình dưới thể hiện cách mà learning rate thay đổi qua từng epoch:
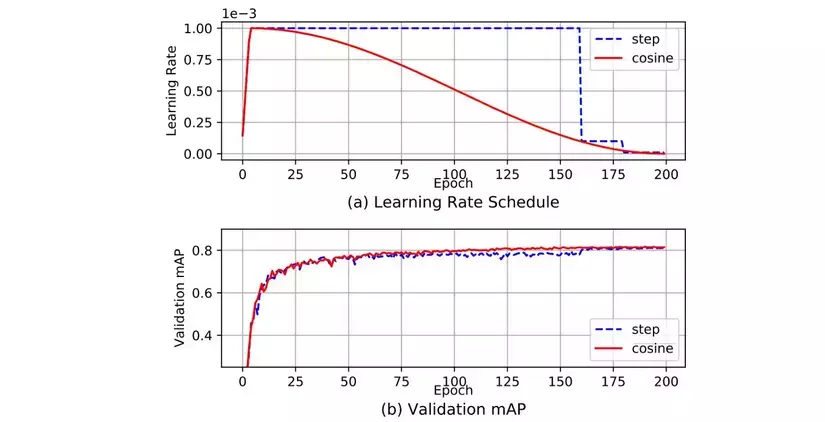
Kết luận
Nhờ những cải tiến trên, mô hình đạt kết quả SOTA về độ chính xác cũng như về tốc độ:
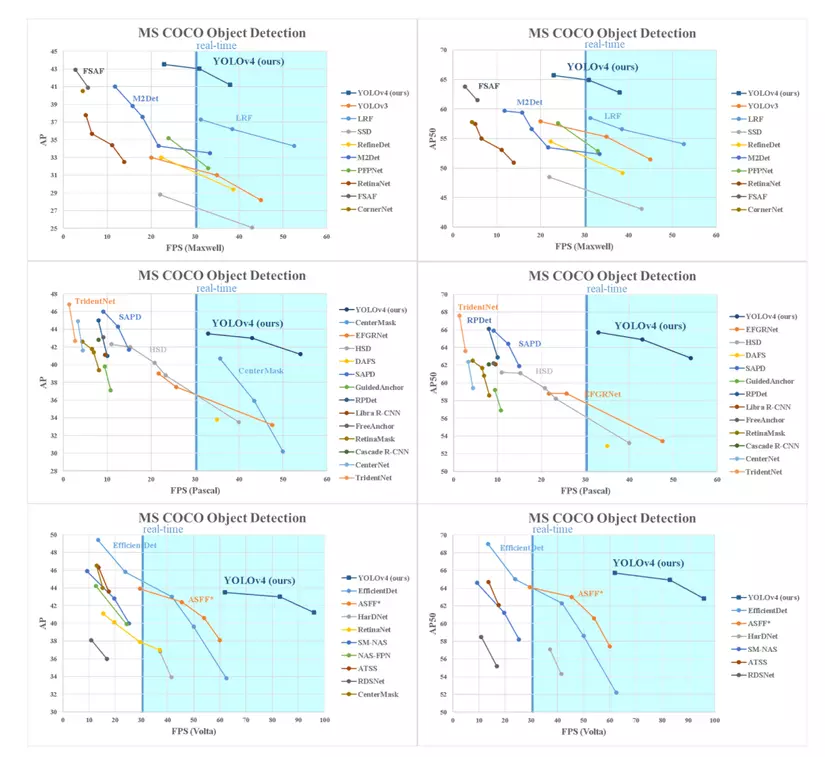
Ngoài ra, nhóm tác giả còn kiểm chứng được một số lượng lớn các features và lựa chọn chúng trong việc cải tiện độ chính xác cho cả classifier và detector. Dưới đâu là hình ảnh so sánh các features được sử dụng:
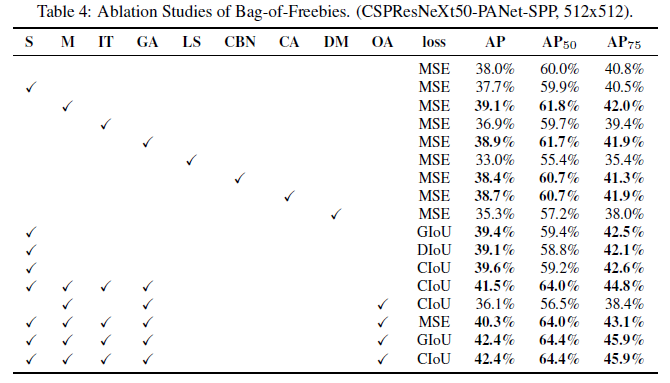
Trong đó:
- S: Eliminate grid sensitivity
- M: Mosaic data augmentation
- IT: IoU threshold – sử dụng multiple anchors
- GA: Genetic algorithms – sử dụng để lựa chọn siêu tham số
- LS: Label smoothing
- CBN: Cross-mini Batch Normalization
- CA: Consine annealing scheduler
- DM: Dynamic mini-batch size – tự động tăng kích thước mini-batch
- OA: Optimized Anchors
- GIoU, CIoU, DIoU, MSE – các loss sử dụng
Tham khảo
- YOLOv4: Optimal Speed and Accuracy of Object Detection
- Tổng hợp kiến thức từ YOLOv1 đến YOLOv5 (Phần 3)
- Review — YOLOv4: Optimal Speed and Accuracy of Object Detection
- YOLOv4 — Version 0: Introduction
- Receptive field là gì? Tại sao nó lại quan trọng đối với CNN?
Tìm hiểu thêm về Pixta Vietnam
🌐 Website: https://pixta.vn/careers
🏠 Fanpage: https://www.facebook.com/pixtaVN
🔖 LinkedIn: https://www.linkedin.com/company/pixta-vietnam/
